

E’ innegabile l’interesse che tutto il mondo IT ha riservato in questi ultimi anni ad OpenStack. Per tutte le maggiori società produttrici di hardware (IBM, HP, CISCO, DELL, etc.), i produttori di sistemi operativi (VMware, Red Hat, Canonical, etc.) e soprattutto i provider (Rackspace ed Amazon in primis) è stato un susseguirsi di annunci, presentazioni, integrazioni e contributi ad OpenStack.
Qual’è la ragione di tutto questo?
La risposta è rappresentata da questo viaggio, in più articoli, all’interno di OpenStack. Partendo dall’introduzione ai concetti si arriverà alla realizzazione di un progetto completo che consenta di valutare e vagliare funzionalità, difficoltà ed applicabilità di un progetto OpenStack.
Sarà un viaggio divertente, non rimane che partire.
Perché OpenStack si sta rivelando così importante?
L’ormai tradizionale paradigma client-server, in progetti in cui la scalabilità e le finestre di picchi di carico sono variabili essenziali all’interno dell’equazione della produttività, presenta evidenti limiti. Rispetto alla costituzione originale di queste architetture moltissime cose sono cambiate, soprattutto nell’ambito web. Ecco quindi nascere l’esigenza di uno strumento che fosse flessibile ed allo stesso momento affidabile.
Questo concetto spiega le motivazioni che possono spingere ad adottare una piattaforma cloud, ma perché fra tutte le piattaforme esistenti si parla sempre di OpenStack?
OpenStack è un progetto aperto.
La sua natura aperta ha fatto sì che tutti i vendor interessati all’introduzione di specifiche funzionalità o determinati ambiti potessero contribuire in maniera attiva e funzionale al progetto, innescando un circolo virtuoso in cui ogni miglioramento apportato per favorire se stessi va a beneficio della comunità.
La sua natura aperta fa sì che chi adotta OpenStack per il proprio ambiente cloud è di fatto esente dal vendor lock-in, ossia l’essere vincolato ad un rivenditore specifico per le proprie tecnologie. Infatti se lo standard OpenStack è garantito, ogni venditore potrà essere valutato pariteticamente agli altri, rendendo così il mercato più competitivo e conveniente per il cliente finale.
Openstack è il simbolo di una rivoluzione
OpenStack è quindi il simbolo di questa rivoluzione cloud che celebra per il web la fine del dogma client-server. In questa serie di articoli verranno introdotti i concetti base di OpenStack, verrà realizzata un’infrastruttura di test e verranno poste le basi per un progetto volto al bilanciamento autonomo del carico di un’infrastruttura.
I presupposti di un progetto OpenStack
Non tutti i progetti sono adatti al cloud. Questo principio sfugge a molti che guardano verso le nuvole e vedono unicamente un posto differente da cui erogare i propri servizi. Esistono dei requisiti da tenere presente per capire se un progetto è adatto al cloud.
Un progetto OpenStack quindi deve essere:
- Non persistente: non deve basarsi sulla persistenza dei dati all’interno delle macchine coinvolte. Questo aspetto non va confuso con l’esigenza di avere uno storage solido e sicuro, si tratta invece di non giudicare le istanze che concorrono al progetto come perenni, ma come componenti utili al loro scopo e liberamente sacrificabili;
- Scalabile: deve supportare applicazioni che nativamente siano in grado di scalare. L’applicazione nasce già dallo sviluppo come pensata per il cloud;
- Dinamico: a fronte di un innalzamento delle richieste ricevute il progetto deve essere in grado in maniera autonoma di gestire le nuove componenti. Gli interventi manuali successivi all’implementazione sulle istanze coinvolte devono essere inesistenti;
- Rapido: deve essere passibile di provisioning, favorendo la velocità di creazione (e distruzione) di nuove istanze;
Se quindi il proprio progetto risponde a questi requisiti ed evidenzia le necessità descritte, allora è giunto il momento di capire in cosa consiste OpenStack.
Le componenti di OpenStack
La parola stack descrive un insieme di entità che concorrono ad uno scopo comune. OpenStack è composto da numerose elementi che devono comunicare fra loro, lo strato di comunicazione passa attraverso due filoni fondamentali: la memorizzazione delle informazioni e la coda delle azioni da svolgere. Queste due azioni sono coperte ciascuna da un elemento specifico:
MySQL
Il database MySQL è necessario per la memorizzazione delle informazioni di configurazione generali del sistema, per la memorizzazione delle informazioni di autenticazione relative a ciascun componente e per il mantenimento dinamico dello stato del sistema.
Ogni azione eseguita all’interno dell’infrastruttura OpenStack è tracciata all’interno del database. L’importanza di questa componente è evidentemente capitale.
RabbitMQ
RabbitMQ è uno scheduler, un software didicato alla gestione delle code ed all’organizzazione delle sequenze di operazioni. Tutti i nodi facenti parte dell’infrastruttura OpenStack comunicano con lo scheduler, ed anche in questo caso è presto spiegato come questa componente ricopra enorme importanza per il regolare funzionamento dell’ambiente.
Determinato quindi il sistema di circolazione e reperimento delle informazioni si può focalizzare l’attenzione sugli elementi peculiari di OpenStack, riassunti in questo diagramma che si trova sul sito ufficiale del progetto:
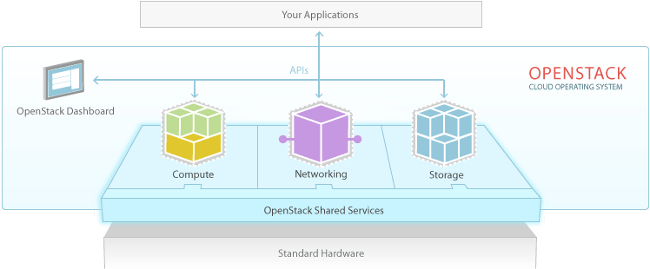
Keystone
Keystone è il software che gestisce il sistema di autenticazione di OpenStack. Il principio su cui si fonda è quello classico degli utenti e dei gruppi, ma di fatto si occupa di gestire le tre tipologie di utenti configurabili in OpenStack:
- Cloud Provider Admins: ossia gli amministratori del sistema OpenStack;
- Tenants: ossia i profili delle compagnie fruitrici dei servizi;
- Users: ossia gli utenti delle compagnie fruitrici dei servizi;
Il concetto di compagnia si riferisce ad un sotto-ambiente interno alla stessa installazione di OpenStack. Applicato ad un provider esso potrebbe essere rappresentato dai clienti, mentre per all’interno di un cloud privato potrebbe essere associato ad un dipartimento interno.
Glance
Glance si occupa del provisioning (ossia di fornire) delle immagini all’interno dell’ambiente. Questa componente fornisce un bacino di istanze vergini preconfigurate, disponibile ai fruitori dei servizi, per effettuare il deploy (ossia la messa in produzione) dell’istanza desiderata all’interno del proprio ambiente.
Le immagini sono supportate nei formati KVM qcow, Aws, VMWare purché esista su queste un Master Boot Record.
Nova
Nova è il compute service, un servizio che permette di gestire i sistemi virtuali erogati all’interno dell’ambiente. All’interno della macchina definita controller il servizio nova-api guiderà l’avvio e la terminazione delle istanze comandando la sua controparte nova-compute, attiva su tutte le macchine hypervisor facenti parte della struttura OpenStack.
Le decisioni su dove e come le istanze dovranno essere avviata saranno gestite dal servizio nova-compute-service (basato su libvirt).
Horizon
Horizon è l’interfaccia web dalla quale è possibile controllare agevolmente le istanze in modalità point-and-click oltre che le immagini gestite da Glance. Il software Horizon è basato sul modulo wsgi del webserver Apache.
Sebbene le componenti per un progetto base OpenStack (e lo si vedrà nel prossimo articolo quando verrà messo in pratica quanto illustrato) potrebbero considerarsi esaurite qui, c’è un ultimo aspetto da tenere presente, come è deducibile dallo schema: lo storage.
In un setup base le macchine possono essere erogate direttamente dai dischi degli hypervisor, ma in ambienti di larga scala ciò potrebbe non essere auspicabile. In questi casi fare riferimento ad un gestore dello spazio centralizzato permetterebbe di utilizzare gli hypervisor come semplici erogatori, valorizzando la scalabilità generale del progetto.
Cinder
In origine parte del progetto Nova (chiamato nova-volume) e dal 2012 progetto a se stante, Cinder è il servizio che fornisce il block storage per le istanze, uno storage gestito e centralizzato che funziona da dispositivo a blocchi per le virtual machines. Le macchine virtuali risiedono quindi su un device dedicato, definito sulla base di quello che è la modalità con cui l’hypervisor ha accesso allo storage.
Cinder supporta diverse modalità per essere visto dagli hypervisors: è possibile infatti utilizzare dischi locali o sistemi storage esterni, quali NFS, FibreChannel, DRBD o iSCSI.
Swift
A differenza di Cinder, Swift è un servizio di storage online che si occupa di rendere disponibile spazio all’interno dell’ambiente OpenStack mediante la modalità object storage. I dati non vengono registrati direttamente su dispositivi a blocchi, ma preventivamente convertiti in oggetti binari, distribuiti all’interno di più device in modo da garantirne la massima accessibilità oltre che la replica.
Swift è compatibile con il servizio di storage Amazon S3 e funziona con lo stesso principio: fornire uno storage web accessibile e scalabile.
Conclusioni
In questa lunga introduzione sono stati illustrati filosofia, componenti e soprattutto potenzialità di OpenStack, ma sebbene la lettura possa essere apparsa lunga, questa tocca appena la superficie dell’universo relativo a questo grande progetto.
Nel prossimo articolo verrà avviato uno studio di fattibilità vero e proprio con lo scopo di mettere su strada tutti i vari software che compongono OpenStack. L’obiettivo finale sarà arrivare a gestire un abbozzo di infrastruttura a cui mano a mano verranno aggiunte parti con lo scopo di arrivare ad ottenere un’installazione completa e operativa di OpenStack.
La serie
Ecco tutti gli articoli della serie “OpenStack, appunti di viaggio“:
- Parte prima: introduzione
- Parte seconda: configurazione ambiente operativo
- Parte terza: dashboard e deploy massivo di istanze personalizzate
Da sempre appassionato del mondo open-source e di Linux nel 2009 ho fondato il portale Mia Mamma Usa Linux! per condividere articoli, notizie ed in generale tutto quello che riguarda il mondo del pinguino, con particolare attenzione alle tematiche di interoperabilità, HA e cloud.
E, sì, mia mamma usa Linux dal 2009.












Lascia un commento