
![]()
Sulle nostre pagine potete leggere abbastanza spesso notizie relative al mondo container su Linux, specialmente riguardo Docker e le relative applicazioni cluster, quali Kubernetes o Swarm.
La parte “noiosa” di dover testare (in locale) sistemi di clustering è spesso il dover avere a che fare con diverse VM ed, anche se ci sono sistemi che semplificano questo passaggio, come Vagrant (per citarne uno), ogni macchina virtuale lanciata sul nostro sistema occupa risorse e spazio disco.
Questi “problemi” si amplificano ulteriormente quando, ad esempio, abbiamo la necessità di generare un nuovo cluster con l’idea di distruggerlo in breve tempo (ad esempio al fine di testare una feature specifica che potrebbe impattare l’ambiente di studio che già abbiamo sulla macchina).
Evidentemente è un problema decisamente sentito, tant’è che alcuni utenti Docker hanno creato ed, ovviamente, distribuito a tutti su GitHub il progetto play-with-docker:
Play With Docker gives you the experience of having a free Alpine Linux Virtual Machine in the cloud where you can build and run Docker containers and even create clusters with Docker features like Swarm Mode.
Play With Docker ti da la possibilità di avere una virtual machine Alpine Linux gratuita nel cloud, in cui puoi creare ed eseguire container Docker, ed anche creare cluster con le funzionalità di Docker come lo Swarm Mode.
Insomma, si tratta di un’applicazione scritta in Go che permette di erogare in locale un sito web in cui è possibile avere una sessione a tempo in cui sarà possibile eseguire, creare, distruggere sia semplici container Docker, che interi cluster Swarm. Cosa ancora più interessante, è stata messa online un sito pubblico in cui Play With Docker è utilizzabile da chiunque: http://play-with-docker.com/.
Per chi non fosse interessato allo specifico progetto di Play With Docker, avviso che questo articolo può essere letto anche per avere un’infarinatura di base (ma molto base) di Swarm e delle funzionalità clustering integrate nel progetto Docker.
Conosciamo meglio l’ambiente
Ma andiamo a vedere cosa possiamo fare di interessante: una volta collegati al sito (ed aver verificato di essere delle persone), ci troviamo davanti a questa schermata:
 In questa schermata possiamo notare tre macro sezioni:
In questa schermata possiamo notare tre macro sezioni:
- In alto a sinistra è presente il contatore del tempo rimanente ed un pulsante per chiudere la sessione. Sia alla scadenza delle 4 ore che nel caso decidessimo di chiudere la nostra sessione è importante ricordare che tutte le modifiche effettuate verranno distrutte.
- Sempre sulla sinistra abbiamo la lista delle istanze (nodi) che abbiamo creato, oltre alla voce “Add new instance” che ci permette di creare tutti i nodi di cui abbiamo bisogno.
- Infine, come vedremo più avanti, nella parte rimanente della pagina saranno disponibili informazioni sul nodo sul quale stiamo lavorando, oltre che un terminale funzionante in cui eseguiremo i comandi
Creiamo quindi la nostra prima istanza e, come anticipato, vediamo che oltre al terminale sono disponibili informazioni quali l’indirizzo IP del nodo, l’uso di memoria e di CPU.
 Da questo punto abbiamo un sistema Linux funzionante su cui possiamo far girare container Docker. Possiamo provare tranquillamente ad eseguire il container ‘hello-world’, come ogni guida consiglia di fare come prima operazione:
Da questo punto abbiamo un sistema Linux funzionante su cui possiamo far girare container Docker. Possiamo provare tranquillamente ad eseguire il container ‘hello-world’, come ogni guida consiglia di fare come prima operazione:
$ docker run hello-world
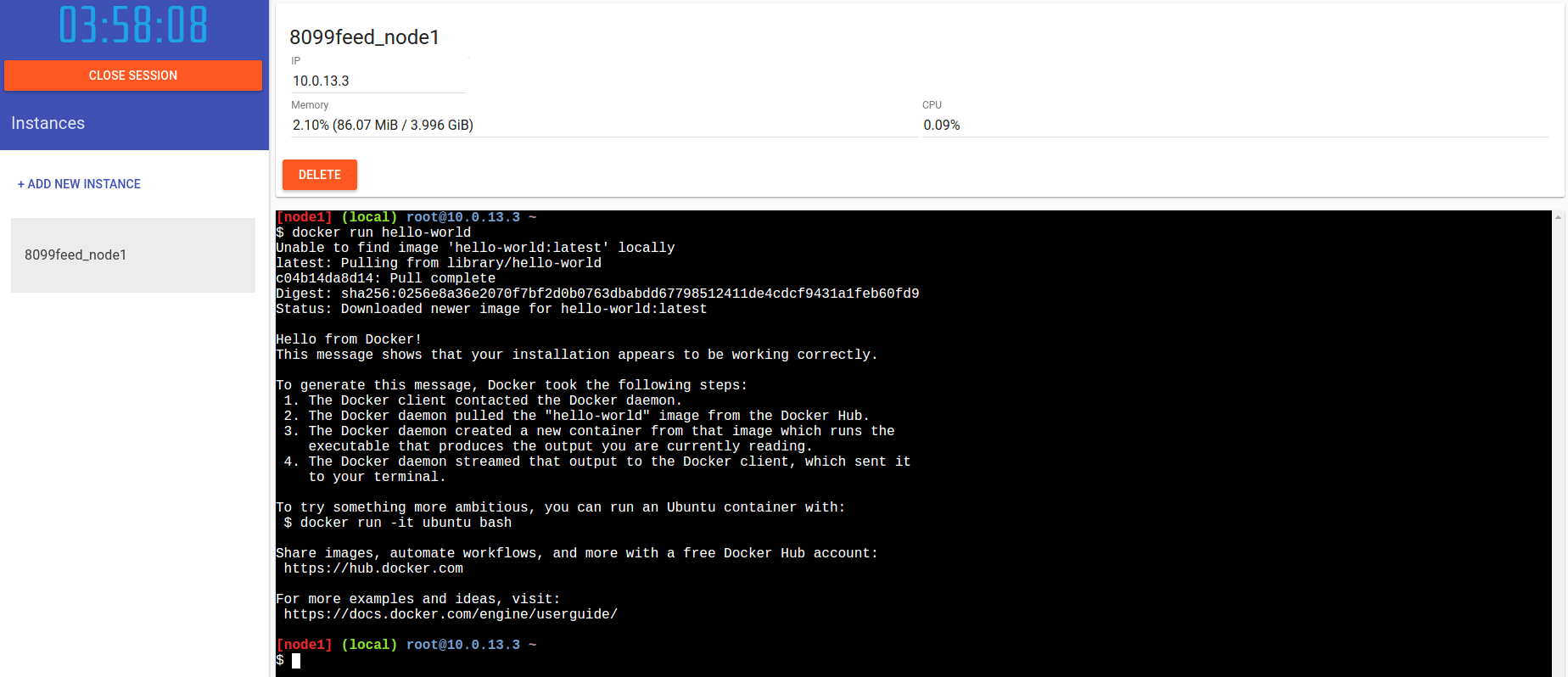
Semplice e veloce! Andiamo quindi a ripulire la situazione con “docker rm” e “docker rmi” per partire da zero (potremmo anche cancellare e creare un nuovo nodo, o semplicemente ignorare quanto fatto fino ad ora).
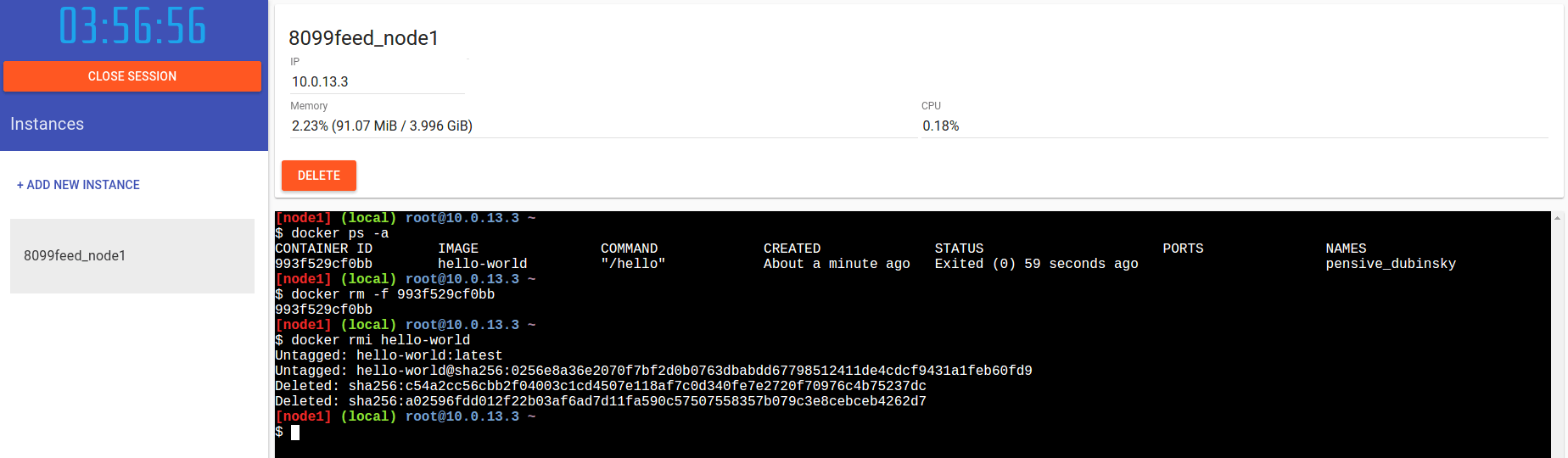
Già qui potete sbizzarrirvi a testare immagini proventienti dal docker hub o a creare immagini ex-novo; andiamo adesso a vedere come poter iniziare a “giocare” rapidamente con un cluster Swarm.
Creare un cluster Swarm
Per chi non lo conoscesse Swarm è la soluzione integrata di Docker per la gestione di un cluster in grado di eseguire container o, come li definisce Swarm stesso, servizi; un servizio è formato da uno o più container, espone una porta, ed è in grado di scalare facilmente in termini di numero di container. L’intero strato di bilanciamento network, nella sua configurazione più semplice, è interamente gestito da Docker stesso, e permette di astrarre il servizio dai container reali che lo fanno girare.
Swarm richiede almeno 2 nodi (un manager ed un worker) per funzionare, anche se per motivi di ridondanza è sempre avere almeno un paio di worker e due o più manager. Un sacco di VM!
Al momento abbiamo un singolo nodo, inizializziamo su di esso il cluster (questo promuove il nodo, automaticamente, come manager del cluster stesso):
$ docker swarm init --advertise-addr 10.0.13.3
Swarm initialized: current node (jkr2vnv7ntyj0p0zgmdj5t17c) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join \
--token SWMTKN-1-06hpb763v16zbsplkmbw9yp3uyt5wwti5jyg6kwq8jljk657gw-4p9yazl13uz9ipgxrw3ly8eq6 \
10.0.13.3:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
Ovviamente, l’indirizzo IP del comando andrà modificato in accordo con l’ip del nodo su cui lanciate il comando.
Come potete notare dallo screenshot, l’interfaccia dei nodi sulla sinistra cambia, aggiungendo a fianco al nome del nodo un’icona blu piena. Questo identifica rapidamente che quel nodo è il manager di un cluster swarm.
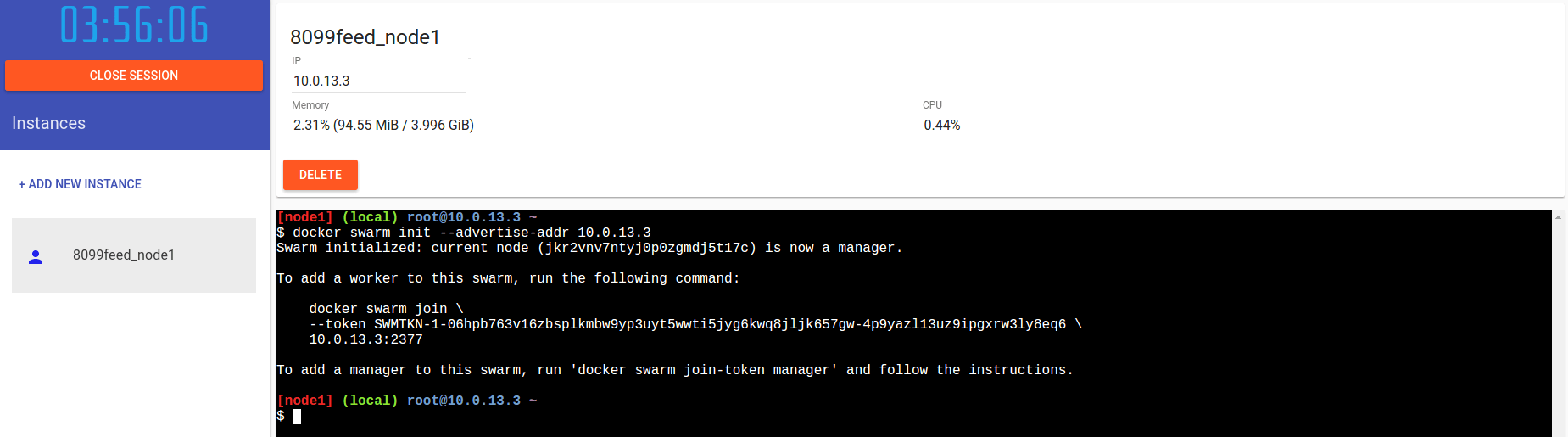
Il comando ci fornisce anche in output già i comandi per fare join di nuovi worker al cluster. Più facile di così…
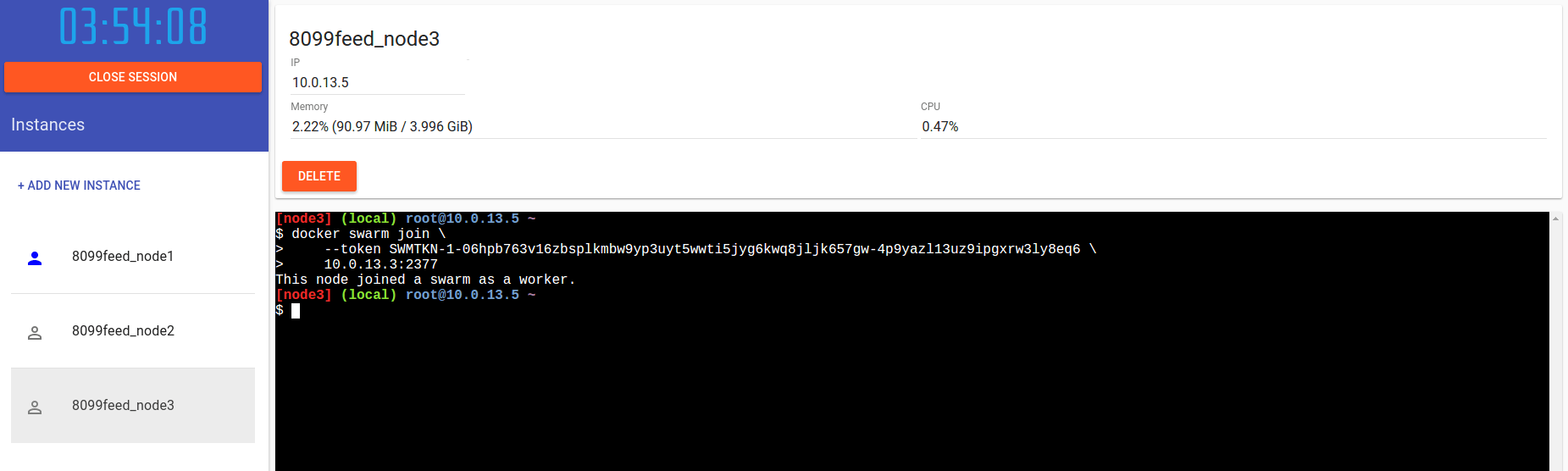
Procediamo quindi a creare altre due nuove istanze ed ad eseguire il comando riportato in output:
$ docker swarm join \
> --token SWMTKN-1-06hpb763v16zbsplkmbw9yp3uyt5wwti5jyg6kwq8jljk657gw-4p9yazl13uz9ipgxrw3ly8eq6 \
> 10.0.13.3:2377
This node joined a swarm as a worker.
Vediamo che l’interfaccia grafica è cambiata ulteriormente. I due nuovi nodi, i worker del nostro cluster, vengono rappresentati con la stessa icona del primo nodo, ma senza il riempimento. Questo identifica i worker:
Dicevo all’inizio che per la ridondanza di solito si utilizzano almeno due manager nel cluster. Noi vogliamo lavorare su un ambiente di test che sia il più simile possibile ad una situazione reale, procediamo quindi a creare altre due istanze che andremo a promuovere come manager del cluster.
Spostiamoci sul primo nodo (l’attuale unico manager) e, dall’output dell’inizializzazione del cluster Swarm, prendiamo il comando per ottenere il token necessario alla join di nuovi manager:
$ docker swarm join-token manager
Questo comando produrrà in output l’istruzione da lanciare sui nodi per farli diventare manager del nostro cluster. Creiamo altre due istanze e procediamo ad eseguire il comando fornito su di esse:
$ docker swarm join \
> --token SWMTKN-1-06hpb763v16zbsplkmbw9yp3uyt5wwti5jyg6kwq8jljk657gw-ew1s2bisybv789v86fmka2v9x \
> 10.0.13.3:2377
This node joined a swarm as a manager.
Ecco la situazione finale:
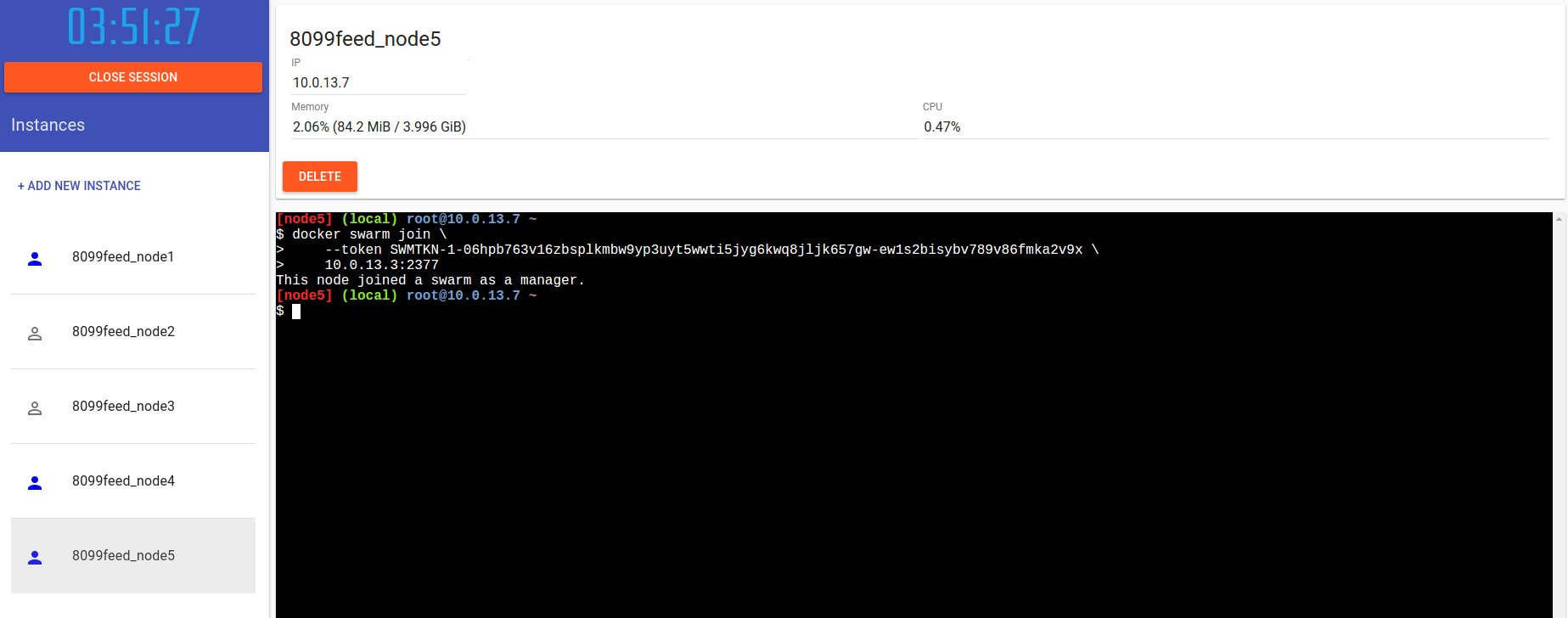
Il nostro cluster è quindi composto da:
- node1, node4 e node5 come manager
- node2 e node3 come worker
Possiamo vedere lo stato del cluster lanciando, da uno qualsiasi dei manager, il comando:
$ docker info
Containers: 0
Running: 0
Paused: 0
Stopped: 0
Images: 0
Server Version: 1.13.0-rc5
Storage Driver: overlay2
Backing Filesystem: xfs
Supports d_type: true
Native Overlay Diff: true
Logging Driver: json-file
Cgroup Driver: cgroupfs
Plugins:
Volume: local
Network: bridge host ipvlan macvlan null overlay
Swarm: active
NodeID: jkr2vnv7ntyj0p0zgmdj5t17c
Is Manager: true
ClusterID: l7dahqkg6phqprkm6fad6ahgh
Managers: 3
Nodes: 5
Orchestration:
Task History Retention Limit: 5
Raft:
Snapshot Interval: 10000
Number of Old Snapshots to Retain: 0
Heartbeat Tick: 1
Election Tick: 3
Dispatcher:
Heartbeat Period: 5 seconds
CA Configuration:
Expiry Duration: 3 months
Node Address: 10.0.13.3
Manager Addresses:
10.0.13.3:2377
10.0.13.6:2377
10.0.13.7:2377
Runtimes: runc
Default Runtime: runc
Init Binary: docker-init
containerd version: 03e5862ec0d8d3b3f750e19fca3ee367e13c090e
runc version: 51371867a01c467f08af739783b8beafc154c4d7
init version: 949e6fa
Security Options:
seccomp
Profile: default
Kernel Version: 4.4.0-51-generic
Operating System: Alpine Linux v3.5 (containerized)
OSType: linux
Architecture: x86_64
CPUs: 16
Total Memory: 120.1 GiB
Name: node1
ID: 6FOS:ALPI:KBOE:H3WA:MWUS:Z3VQ:MILE:VUKY:JINP:4BN6:XVQO:ADIJ
Docker Root Dir: /graph
Debug Mode (client): false
Debug Mode (server): false
Registry: https://index.docker.io/v1/
WARNING: No swap limit support
WARNING: bridge-nf-call-iptables is disabled
WARNING: bridge-nf-call-ip6tables is disabled
Experimental: true
Insecure Registries:
127.0.0.0/8
Live Restore Enabled: false
*NOTA BENE* Seppur possa sembrare strano avere più manager che worker, è da notare che per i cluster Swarm i manager fungono anche da worker. Il che vuol dire che attualmente abbiamo un cluster in grado di supportare 5 container in parallelo per l’esecuzione di un singolo servizio (potrebbero essere anche di più, ma si andrebbe a non avere più parallelismo). L’unica differenza, dunque, tra un worker ed un manager è che sui manager è possibile eseguire i comandi di gestione del cluster e di deploy dei servizi.
Il nostro primo servizio
Quale modo migliore di testare un cluster Swarm se non creare un servizio che eroghi qualcosa? Partiamo facilmente utilizzando l’immagine nginx, che fornisce una semplice configurazione di base del famoso webserver omonimo.
Il comando è estremamente semplice e, come molti comandi docker risponde indicando l’id del servizio che abbiamo appena creato.
$ docker service create --name frontend --replicas 3 -p 8080:80 nginx
sui4g8o6rav8easyjbq74vnd9
I parametri sono molto semplicemente i seguenti:
- –name: Il nome che vogliamo dare al servizio. Nel nostro caso lo abbiamo chiamato ‘frontend’
- –replicas: Il numero di repliche (container) che vogliamo deployare. Partiamo con 3
- -p: Il mapping delle porte. Nginx parte di default erogando la porta 80, noi vogliamo accedervi usando la porta 8080, faremo quindi questo mapping 8080:80
- nginx: Il nome del container su cui si basa il servizio
Questo avrà quindi generato 3 container nginx (su che nodi al momento non lo sappiamo) che erogano il servizio ‘frontend’ sulla porta 8080. Questo significa che contattando la porta 8080 del nostro cluster andremo ad utilizzare uno di questi container. Le logiche di bilanciamento, al momento, sono tutte in mano a docker.
Possiamo andare a caccia dei nostri container eseguendo il comando “docker ps” su ogni nodo per vedere su quali sono attualmente in esecuzione i container nginx:
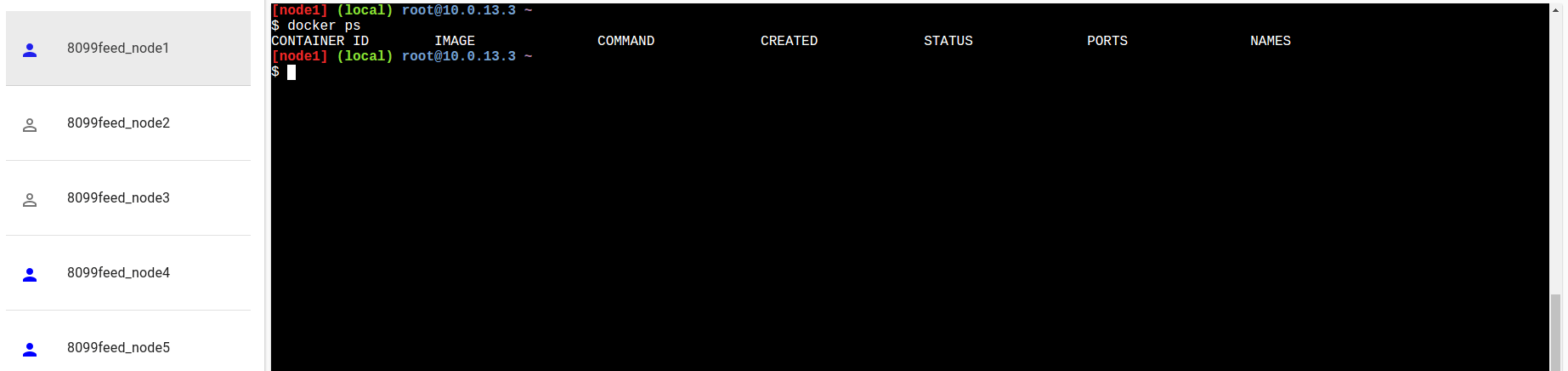

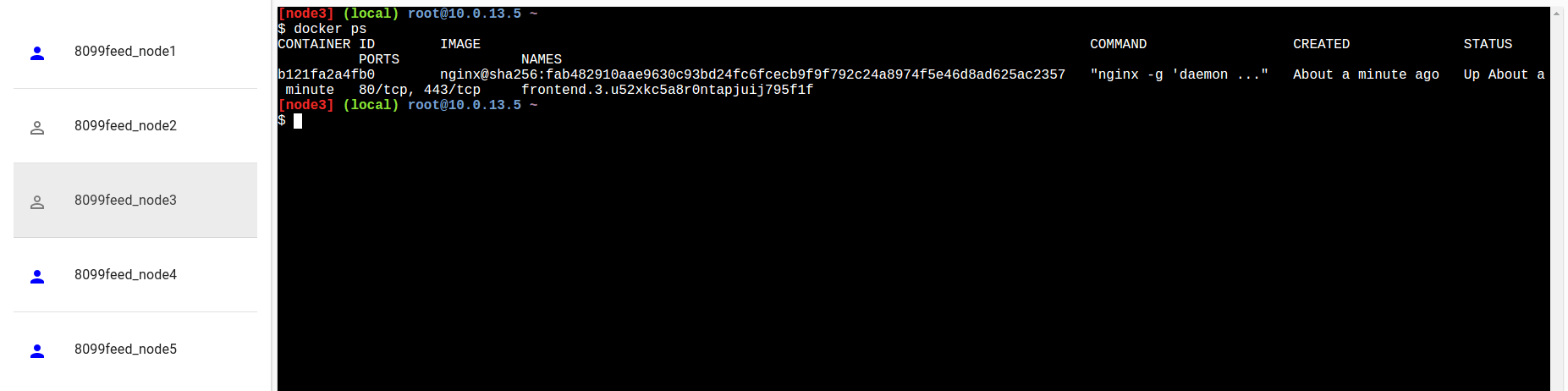
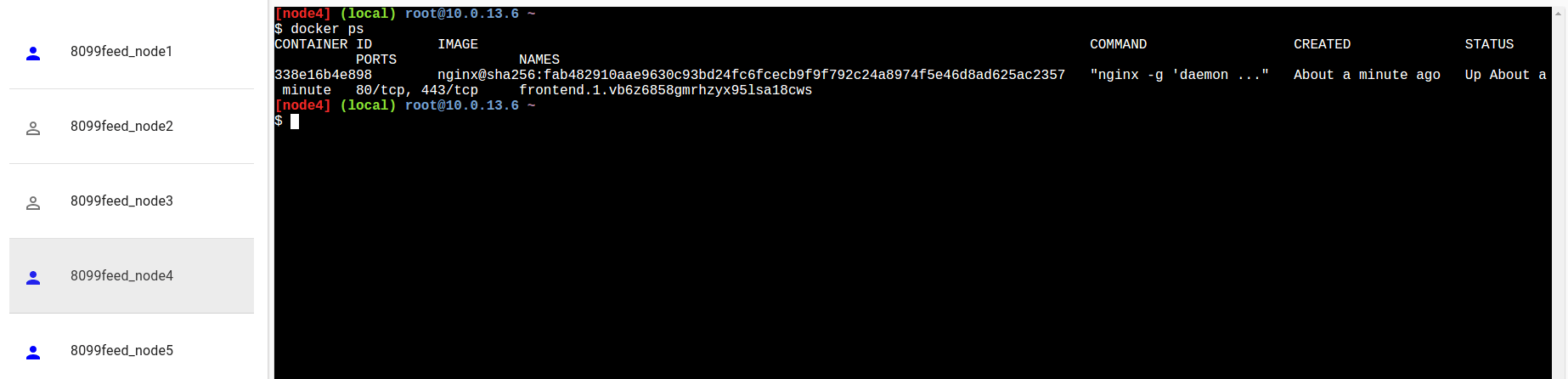
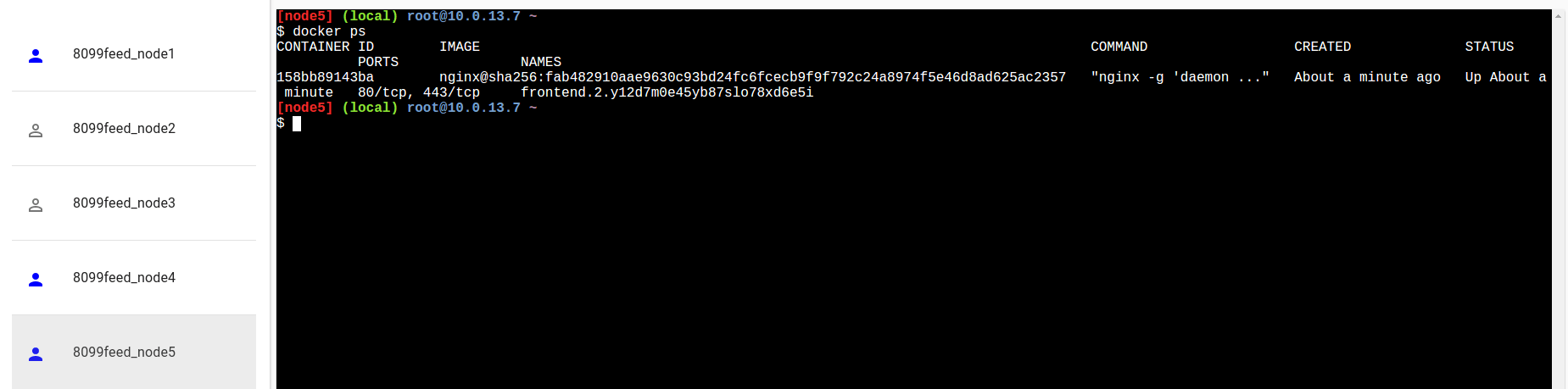
Oppure, più elegantemente, potremmo richiedere ad un manager i darci lo stato del servizio:
$ docker service ls
ID NAME MODE REPLICAS IMAGE
sui4g8o6rav8 frontend replicated 3/3 nginx:latest
ed i nodi su cui stanno girando i vari container:
$ docker service ps frontend
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
irvd6ey10sdq frontend.1 nginx:latest node4 Running Running about 2 minutes ago
zolosd1pdsdd frontend.2 nginx:latest node5 Running Running about 2 minutes ago
7ux2yvk6kgb7 frontend.3 nginx:latest node3 Running Running about 1 minute ago
Nella parte superiore dei nodi manager potete notare che, dopo la creazione del servizio Swarm, è apparso un link nominato come la porta che abbiamo forwardato, ovvero 8080. Facendo click su di esso veniamo rediretti ad un’altra pagina del sito che corrisponde al servizio da noi erogato; ed ecco il nostro servizio frontend in tutto il suo splendore:
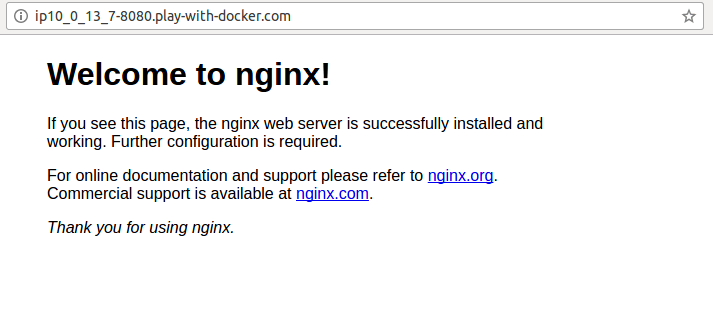
L’immagine di container di nginx scrive direttamente sullo standard output del container stesso i log del webserver. In questo modo, possiamo utilizzare i comandi ‘docker logs’ e ‘docker logs -f’ (con il following, esattamente come il tail) sui container per vedere dove è arrivata la nostra chiamata. Nel nostro caso siamo sul container in esecuzione sul nodo 3:
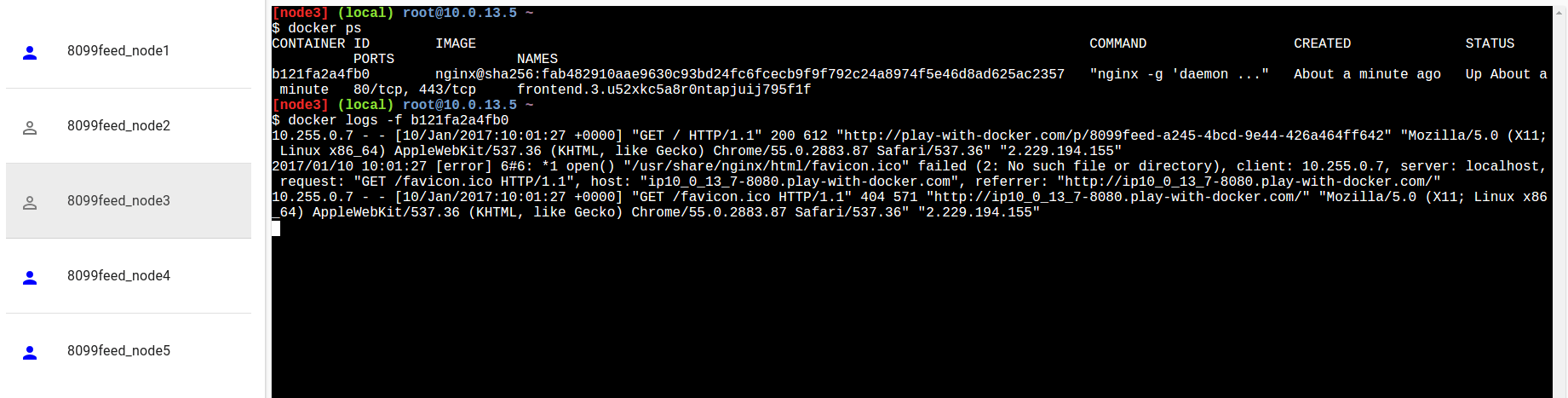
Se vi mettete in follow sui vari container ed provate a chiamare diverse volte il vostro server nginx potrete vedere che le chiamate vengono distribuite tra i vari nodi del cluster:
Scaliamo insieme
Vi dicevo che i servizi Swarm possono scalare rapidamente; così rapidamente che basta il seguente comando:
$ docker service scale frontend=5
frontend scaled to 5
In pratica abbiamo detto a docker di scalare il servizio frontend fino ad avere 5 repliche, in soldoni aggiungendone due a quanto già erogato. Tutta la loro configurazione di rete e la messa sotto bilanciamento network viene fatta in automatico da docker:
$ docker service ls
ID NAME MODE REPLICAS IMAGE
o2of3cwnol96 frontend replicated 5/5 nginx:latest
$ docker service ps frontend
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
irvd6ey10sdq frontend.1 nginx:latest node4 Running Running about 7 minutes ago
zolosd1pdsdd frontend.2 nginx:latest node5 Running Running about 7 minutes ago
7ux2yvk6kgb7 frontend.3 nginx:latest node3 Running Running about 6 minutes ago
uve8jekki3av frontend.4 nginx:latest node2 Running Running 55 seconds ago
jyi2gzsfkhik frontend.5 nginx:latest node1 Running Running 55 seconds ago
Conclusioni
Alla fine questo progetto viene molto comodo in situazioni in cui si devono fare test su ambienti docker/swarm senza andare a toccare l’eventuale nostro ambiente di test già funzionante, e senza dover stressare eccessivamente il nostro caro OS creando e tenendo accese diverse VM.
Ricapitolando, almeno secondo il sottoscritto, di seguito i vantaggi e gli svantaggi di Play With Docker:
- Pro
- Velocità: si crea l’ambiente e lo si estende davvero rapidamente
- Isolamento: se dobbiamo testare specifiche feature, possiamo farlo senza impattare altri ambienti
- Open-Source: certo, avere il sito e non dover installare nulla è comodo, ma pensate anche alla comodità di poterselo erogare in locale e, magari, modificando il codice in modo da togliere la scadenza ed avere diversi ambienti di test (attualmente la limitazione è di 5 sessioni) a lungo termine completamente separato da qualiasi altro
- Contro
- Limitato: funziona bene per Docker, funziona bene per Swarm, non ho avuto modo di provare, ma a sensazione far girare altri ambienti di clustering (eg. Kubernets) potrebbe non essere così agile
- Con scadenza: se devo provare una feature specifica va bene, mi creo rapidamente l’ambiente e la testo; ma se questo test si prolunga nel tempo e/o se vengo interrotto per qualsiasi problema, non c’è modo di mantere le sessioni oltre le 4 ore
Interessante da avere nei bookmark e da usare… se penso a quando muovevo i miei primi passi con Swarm a quante volte distruggevo e ricreavo 5/6 VM (o snapshot) giusto per variare piccoli parametri e vederne il funzionamento mi mordo le mani.
Utente Linux/Unix da più di 20 anni, cerco sempre di condividere il mio know-how; occasionalmente, litigo con lo sviluppatore di Postfix e risolvo piccoli bug in GNOME. Adoro tutto ciò che può essere automatizzato e reso dinamico, l’HA e l’universo container. Autore dal 2011, provo a condividere quei piccoli tips&tricks che migliorano il lavoro e la giornata.














Lascia un commento