
![]()
Proseguiamo il discorso del logging del container iniziato nella scorsa parte. Se non la avete letta, e volete partire dalla base, vi consigliamo di guardare “Docker logging: cosa fa il mio container? [parte 1]“.
Nella scorsa parte abbiamo visto nel dettaglio i seguenti metodi base:
- Modalità “classica”: per avvicinarsi al mondo container, potremmo dover utilizzare questa soluzione per limitare le modifiche di logging al codice delle applicazioni
- Docker default: se non esplicitato un metodo di logging, abbiamo visto come si comporta di default Docker, con il suo driver di log su json
- journald: questo è stato il primo driver di log “esterno”, che ci ha permesso di separare i log dei container da docker e spostarli sull’host locale, andando a garantirne la persistenza
In questa seconda parte inizieremo ad analizzare metodi di log totalmente esterni, ovvero che permettono ai nostri container di scrivere log su sistemi terzi. Ovviamente, anche se la comodità già è sensibile quando si lavora su host Docker singoli, queste soluzioni iniziano a diventare indispensabili quando si lavora con orchestrator di container, quali Swarm o Kubernetes.
In questi casi, infatti, demandiamo l’intera vita dei nostri container a questa sorta di “direttori d’orchestra” che, conoscendo le differenti macchine (nodi) facente parti del cluster, si occupano di creare, monitorare e distruggere i nostri container (fanno molto altro, ma per quanto riguarda lo scopo di questi articoli basti sapere questo).
Quello che bisogna sempre tenere a mente quando si usa un orchestrator è che la vita del container è effimera, ed deve essere assolutamente separata dalla vita del nostro servizio, sia per quanto riguarda l’erogazione che per quanto riguarda i log. Questo apre a nuove prospettive, già perchè se prima i log erano separati per servizio e per macchina, adesso non è più così essendo impossibile da definire, nel tempo, quale (o quali) macchine hanno o stanno tenendo in piedi la nostra applicazione.
Ovviamente, per utilizzare una infrastruttura di questo tipo è necessario pensare ad un sistema centralizzato di gestione dei log, poichè questo diventerà uno dei fulcri del nostro ambiente.
Il laboratorio Swarm
Visto che queste configurazioni specifiche hanno degli utilizzi interessati soprattutto in ambienti cluster, abbiamo deciso di approntare un laboratorio contenente 5 host che prenderanno parte ad un cluster Swarm (CentOS7+docker, 1GB ram), più un nodo considerato “esterno” al cluster. Lo schema di rete è molto semplice:
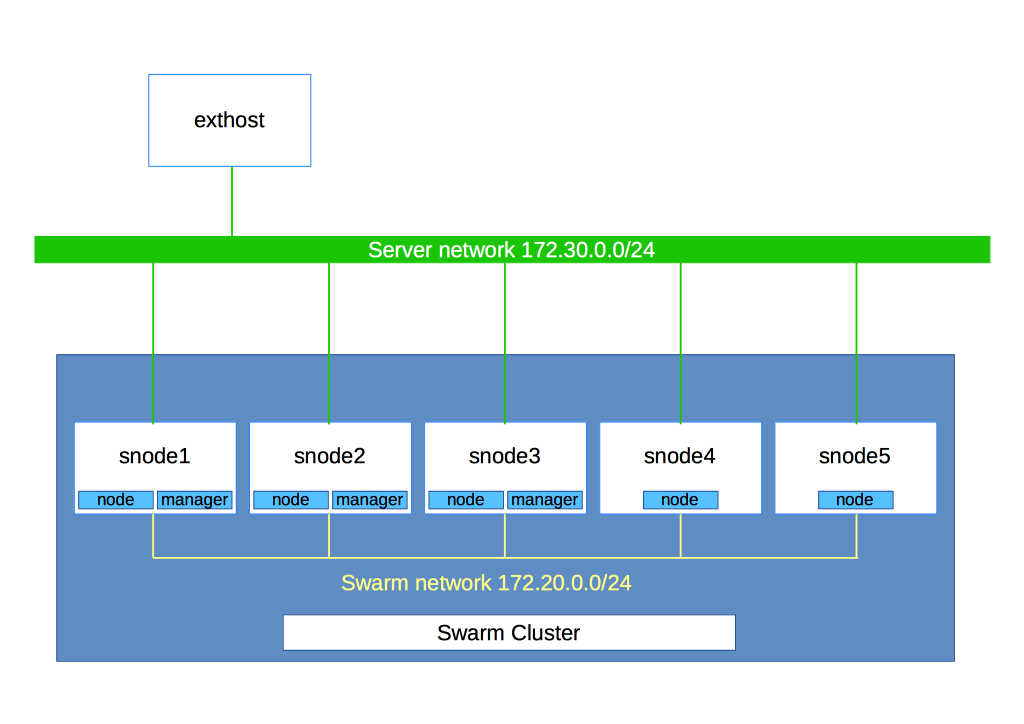
I cinque nodi (snode1, snode2 … snode5) sono attestati su una rete, chiamata Swarm Network, ed hanno IP sequenziali dal 172.20.0.11 al 172.20.0.15. Sono inoltre attestati anche sulla rete “server”, su cui si presentano con gli stessi IP sequenziali (nella relativa classe). Il server esterno exthost, infine, è attestato solo su questa rete, sulla quale ha ip 172.30.0.20.
Per preparare l’ambiente abbiamo utilizzato Vagrant con provider Virtualbox. Per le immagini di partenza, siamo partiti dal box ufficiale di Vagrant centos/7. L’immagine che gira sui vari nodi è una versione personalizzata di quella base, su cui abbiamo solo installato Docker (seguendo la guida ufficiale per la versione CE – Community Edition). Per informazioni riguardanti la creazione di immagini personalizzate Vagrant vi rimandiamo a questo link.
Se volete replicare l’ambiente, potete liberamente scaricare il nostro Vagrantfile da pastebin, posizionarlo in una directory e lanciare:
swarm-test-lab$ vagrant up
Bringing machine 'snode1' up with 'virtualbox' provider...
Bringing machine 'snode2' up with 'virtualbox' provider...
Bringing machine 'snode3' up with 'virtualbox' provider...
Bringing machine 'snode4' up with 'virtualbox' provider...
Bringing machine 'snode5' up with 'virtualbox' provider...
Bringing machine 'exthost' up with 'virtualbox' provider...
...
et voilà, avete anche voi gli host del nostro ambiente di test. Prima di procedere con la creazione del cluster, è necessario sistemare il file /etc/hosts sui cinque nodi, al fine di avere dei nomi parlanti negli output di Swarm. Nulla di complesso, ci basterà lanciare il seguente comando e successivamente riavviare le varie VM:
swarm-test-lab$ for I in 1 2 3 4 5; do vagrant ssh snode${I} -c "sudo sed -i 's/.*snode$I/172.20.0.1$I\ snode$I\ snode$I.localdomain/' /etc/hosts" ; done
...
swarm-test-lab$ vagrant halt
...
swarm-test-lab$ vagrant up
...
Successivamente, inizializziamo il cluster Swarm sul primo nodo assicurandoci di impostare l’indirizzo della Swarm Network per l’advertising:
swarm-test-lab$ vagrant ssh snode1
Last login: Tue Mar 28 11:16:07 2017 from 10.0.2.2
[vagrant@snode1 ~]$ sudo docker swarm init --advertise-addr 172.20.0.11
Swarm initialized: current node (q81jcofcyj74dmsign74pkm4f) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join \
--token SWMTKN-1-5g9o4hkgcw7qwsnidcqv6s6ru6fzpyuh8zmlk86exi9rbmhwev-evdx1w3v28quqjqr3r8j3mt0c \
172.20.0.11:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
Con questo comando di join, possiamo rapidamente far diventare tutti gli altri nodi membri del cluster:
[vagrant@snode1 ~]$ exit
logout
Connection to 127.0.0.1 closed.
swarm-test-lab$ for i in 2 3 4 5; do vagrant ssh snode${i} -c "sudo docker swarm join --token SWMTKN-1-5g9o4hkgcw7qwsnidcqv6s6ru6fzpyuh8zmlk86exi9rbmhwev-evdx1w3v28quqjqr3r8j3mt0c 172.20.0.11:2377"; done
This node joined a swarm as a worker.
Connection to 127.0.0.1 closed.
...
Ed infine, promuoviamo i nodi snode2 e snode3 ad essere manager del cluster Swarm:
swarm-test-lab$ vagrant ssh snode1
Last login: Tue Mar 28 12:47:53 2017 from 10.0.2.2
[vagrant@snode1 ~]$ sudo docker node promote snode2 snode3
Node snode2 promoted to a manager in the swarm.
Node snode3 promoted to a manager in the swarm.
La situazione finale che volevamo ottenere è dunque questa:
[vagrant@snode1 ~]$ sudo docker node ls
ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS
5mqp7ddj9pbrzealb6q37eydt snode3 Ready Active Reachable
q81jcofcyj74dmsign74pkm4f * snode1 Ready Active Leader
qkgl3xyksy7w2i9rxqehto8sj snode5 Ready Active
y89uqvl60589rfhf4msmvgul2 snode4 Ready Active
yuf3mohqztu260pht5y969xwt snode2 Ready Active Reachable
Ora che il nostro laboratorio è pronto, andiamo a vedere quali ulteriori driver di log Docker ci mette a disposizione.
syslog
Sicuramente uno dei sistemi di log centralizzato presente da più tempo (come anche uno di quelli più supportato anche da apparati hardware) è il buon vecchio syslog. Oramai presente di default (in una delle sue sfumature) su qualsiasi distribuzione Linux, viene normalmente configurato come demone di log locale per le macchine.
Inoltre, può essere semplicemente configurato per accettare messaggi di log via tcp o udp, metodo che riesce a sfruttare Docker proprio per remotizzare l’invio degli stessi.
Innanzi tutto andiamo a configurarlo; da una macchina CentOS 7 (il nostro exthost, ad esempio), basta modificare il file /etc/rsyslog.conf e decommentare le righe per l’apertura delle porte sui diversi protocolli:
# Provides UDP syslog reception $ModLoad imudp $UDPServerRun 514 # Provides TCP syslog reception $ModLoad imtcp $InputTCPServerRun 514
Una volta presenti queste righe dobbiamo trovare il modo di separare i log di Docker da quelli utilizzati dal sistema. Per questo, rsyslog mette a disposizione diverse facility chiamate local, numerate da 0 a 7. La 7 viene utilizzata da CentOS per i messaggi di boot, quindi scegliamone liberamente una delle altre. Personalmente ho scelto la 6 poichè il nome “Docker” contiene 6 lettere. Aggiungiamo quindi la entry indicando quella facility in che file dovrà salvare i log aggiungendo questa riga alla configurazione:
# Docker logging local6.* /var/log/docker/docker.log
Creiamo dunque la directory e riavviamo il servizio:
[vagrant@exthost ~]$ sudo mkdir /var/log/docker
[vagrant@exthost ~]$ sudo systemctl restart rsyslog
Siamo ora pronti per scoprire questo driver di logging di Docker. Lanciamo quindi (da uno dei nodi master del cluster) il nostro usuale container che fa ping su Google, indicando il driver syslog per il logging. Nella sua configurazione più semplice, questo driver richiede solo che gli si indichi il protocollo e l’IP di destinazione dei log e la facility in cui loggare:
[vagrant@snode1 ~]$ docker service create --name 'ping-goole' --log-driver syslog --log-opt syslog-address=tcp://172.30.0.20:514 --log-opt syslog-facility=local6 alpine ping 8.8.8.8
2lucvk2bnbudd6c4nom94tnv4
[vagrant@snode1 ~]$ docker service ls
ID NAME MODE REPLICAS IMAGE
2lucvk2bnbud ping-goole replicated 1/1 alpine:latest
Come potete notare, essendo su un cluster Swarm, abbiamo utilizzato un comando leggermente diverso per lanciare il container, ovvero “docker service”. Questo ha creato un servizio chiamato ‘ping-google’ che consiste in N container che eseguono l’immagine alpine con il comando ‘ping 8.8.8.8’. Al momento è presente una sola replica, quindi un singolo container.
Se andiamo sul nostro server di syslog, vedremo il file docker.log che contiene l’output del container appena lanciato:
[vagrant@exthost ~]$ cd /var/log/docker/
[vagrant@exthost docker]$ sudo tail -f docker.log
Mar 28 13:32:14 172.30.0.13 dc68b5a001b6[1209]: PING 8.8.8.8 (8.8.8.8): 56 data bytes
Mar 28 13:32:14 172.30.0.13 dc68b5a001b6[1209]: 64 bytes from 8.8.8.8: seq=0 ttl=61 time=24.851 ms
Mar 28 13:32:15 172.30.0.13 dc68b5a001b6[1209]: 64 bytes from 8.8.8.8: seq=1 ttl=61 time=24.973 ms
Mar 28 13:32:16 172.30.0.13 dc68b5a001b6[1209]: 64 bytes from 8.8.8.8: seq=2 ttl=61 time=24.219 ms
Mar 28 13:32:17 172.30.0.13 dc68b5a001b6[1209]: 64 bytes from 8.8.8.8: seq=3 ttl=61 time=41.283 ms
...
E qui si iniziano a vedere le differenze sostanziali. Come avrete notato, docker service riporta informazioni sul servizio ma, ad esempio, non riporta assolutamente su quali nodi questo sta girando. Per vederlo dobbiamo utilizzare il comando ps:
[vagrant@snode1 ~]$ docker service list
ID NAME MODE REPLICAS IMAGE
2lucvk2bnbud ping-goole replicated 1/1 alpine:latest
[vagrant@snode1 ~]$ docker service ps 2lucvk2bnbud
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
oxdh5gantqov ping-goole.1 alpine:latest snode3 Running Running 3 minutes ago
Vediamo che adesso è in esecuzione sul nodo snode3, ma questo non è stata una nostra decisione. Così come non è una nostra decisione decidere dove istanziare altri container nel caso dicessimo, ad esempio, che questo servizio deve funzionare con 4 repliche:
[vagrant@snode1 ~]$ docker service scale 2lucvk2bnbud=4
2lucvk2bnbud scaled to 4
[vagrant@snode1 ~]$ docker service list
ID NAME MODE REPLICAS IMAGE
2lucvk2bnbud ping-goole replicated 4/4 alpine:latest
[vagrant@snode1 ~]$ docker service ps 2lucvk2bnbud
ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS
oxdh5gantqov ping-goole.1 alpine:latest snode3 Running Running 5 minutes ago
ouoputxbbyz8 ping-goole.2 alpine:latest snode1 Running Running 11 seconds ago
d6ap8pmn6mz1 ping-goole.3 alpine:latest snode5 Running Running 8 seconds ago
uvk5tzaqx6zv ping-goole.4 alpine:latest snode2 Running Running 8 seconds ago
Se andiamo a vedere i log del syslog, notiamo che tutte le istanze stanno loggando correttamente:
[vagrant@exthost docker]$ sudo tail -5 docker.log
Mar 28 13:53:17 172.30.0.13 dc68b5a001b6[1209]: 64 bytes from 8.8.8.8: seq=1262 ttl=61 time=25.636 ms
Mar 28 13:53:17 172.30.0.12 7ca9b859af21[1204]: 64 bytes from 8.8.8.8: seq=938 ttl=61 time=102.046 ms
Mar 28 13:53:15 172.30.0.11 3d351d9395a7[1204]: 64 bytes from 8.8.8.8: seq=940 ttl=61 time=46.660 ms
Mar 28 13:53:14 172.30.0.15 b779ceb7fa18[1205]: 64 bytes from 8.8.8.8: seq=935 ttl=61 time=24.425 ms
Mar 28 13:53:18 172.30.0.13 dc68b5a001b6[1209]: 64 bytes from 8.8.8.8: seq=1263 ttl=61 time=58.506 ms
Cancelliamo il servizio così da fermare il logging:
[vagrant@snode1 ~]$ docker service rm 2lucvk2bnbud
2lucvk2bnbud
Siamo riusciti quindi a risolvere il problema della permamenza dei log accentrandoli su un servizio esterno. Ora, se pensate bene alla soluzione, però, vi salterà all’occhio che ne abbiamo introdotto un altro: la separazione.
Già perchè se è necessario fare in modo che i log sopravvivano alla vita dei container, è altrettanto utile che restino comunque leggibili.
Proviamo a rilanciare il servizio che fa ping a google e creiamo un altro servizio che, invece, pinga (ad esempio) miamammausalinux.org:
[vagrant@snode1 ~]$ docker service create --name 'ping-google' --log-driver syslog --log-opt syslog-address=tcp://172.30.0.20:514 --log-opt syslog-facility=local6 alpine ping 8.8.8.8
wn6f6dvcbrausbths1g05l9dd
[vagrant@snode1 ~]$ docker service create --name 'ping-mmul' --log-driver syslog --log-opt syslog-address=tcp://172.30.0.20:514 --log-opt syslog-facility=local6 alpine ping www.miamammausalinux.org
l2kzfrv1z2xasgwpde78qzovf
[vagrant@snode1 ~]$ docker service ls
ID NAME MODE REPLICAS IMAGE
l2kzfrv1z2xa ping-mmul replicated 1/1 alpine:latest
wn6f6dvcbrau ping-google replicated 1/1 alpine:latest
Andiamo quindi a vedere il log sul nostro syslog:
[vagrant@exthost docker]$ sudo tail -4 docker.log
Mar 28 14:05:07 172.30.0.11 c2dd82699913[1204]: 64 bytes from 46.4.105.174: seq=29 ttl=61 time=24.781 ms
Mar 28 14:05:08 172.30.0.13 88ceadff73f4[1209]: 64 bytes from 8.8.8.8: seq=47 ttl=61 time=22.866 ms
Mar 28 14:05:08 172.30.0.11 c2dd82699913[1204]: 64 bytes from 46.4.105.174: seq=30 ttl=61 time=23.231 ms
Mar 28 14:05:09 172.30.0.13 88ceadff73f4[1209]: 64 bytes from 8.8.8.8: seq=48 ttl=61 time=22.517 ms
Ora, non solo i log di entrambi i servizi finisco tutti dentro il file docker.log, ma è anche difficile separare uno dall’altro (ok, qui ci sono gli IP che parlano per noi, ma pensate in situazioni più estese e complesse).
Possiamo però sfruttare una feature di syslog unita ad una feature di docker per riuscire a separare i log per servizio: i tag!
Questi possono essere utilizzati da syslog per generare dinamicamente i nomi dei file di log, e sono previsti come opzione da Docker per questo particolare log driver.
Procediamo quindi andando a rimpiazzare la entry precedentemente fatta relativa alla facility:
# Docker loggin
local6.* /var/log/docker/docker.log
e la sostituiamo in questo modo:
# Docker loggin
$template DynaFile,"/var/log/docker/%programname%.log"
local6.* -?DynaFile
Ricordiamoci di riavviare il demone. Ora, possiamo lanciare lo stesso servizio di prima, andando ad impostare il nome ‘ping-google’ come tag per il logging:
[vagrant@snode1 ~]$ docker service create --name 'ping-google' --log-driver syslog --log-opt syslog-address=tcp://172.30.0.20:514 --log-opt syslog-facility=local6 --log-opt tag=ping-google alpine ping 8.8.8.8
b190p35maiozjk3mqxp91iarr
[vagrant@snode1 ~]$ docker service ls
ID NAME MODE REPLICAS IMAGE
b190p35maioz ping-google replicated 1/1 alpine:latest
Guardiamo il syslog? Ecco il nuovo arrivato:
[vagrant@exthost docker]$ ls -l
total 512
-rw-------. 1 root root 519646 Mar 28 13:19 docker.log
-rw-------. 1 root root 3937 Mar 28 13:38 ping-google.log
[vagrant@exthost docker]$ sudo tail -2 ping-google.log
Mar 28 14:33:19 172.30.0.13 ping-google[1209]: 64 bytes from 8.8.8.8: seq=63 ttl=61 time=23.509 ms
Mar 28 14:33:20 172.30.0.13 ping-google[1209]: 64 bytes from 8.8.8.8: seq=64 ttl=61 time=23.259 ms
Se lanciamo un altro servizio similare, ricordiamoci di cambiare il tagging sui log:
[vagrant@snode1 ~]$ docker service create --name 'ping-mmul' --log-driver syslog --log-opt syslog-address=tcp://172.30.0.20:514 --log-opt syslog-facility=local6 --log-opt tag=ping-mmul alpine ping www.miamammausalinux.org
oskkew1jf1f60rlwxd394z9zw
Ed ecco i nostri log ben separati:
[vagrant@exthost docker]$ ls -l
total 528
-rw-------. 1 root root 519646 Mar 28 13:19 docker.log
-rw-------. 1 root root 13877 Mar 28 13:40 ping-google.log
-rw-------. 1 root root 1728 Mar 28 13:40 ping-mmul.log
[vagrant@exthost docker]$ sudo tail -1 ping-google.log
Mar 28 14:35:09 172.30.0.13 ping-google[1209]: 64 bytes from 8.8.8.8: seq=173 ttl=61 time=22.299 ms
[vagrant@exthost docker]$ sudo tail -1 ping-mmul.log
Mar 28 14:35:12 172.30.0.15 ping-mmul[1205]: 64 bytes from 46.4.105.174: seq=53 ttl=61 time=23.128 ms
Missione compiuta: abbiamo remotizzato i nostri log, ci siamo garantiti un certo grado di separazione e, soprattutto, la possibilità di mantenere i log oltre la vita dei container. Ottimo lavoro!
GELF
Se il log driver syslog permette, sfruttando un protocollo utilizzato da anni, di andare ad esternalizzare il logging dei container, risulta chiaro che è chiaramente pensato per lavorare con concetti di server/servizi; certo, è possibile riuscire a creare un pochino di separazione negli stessi, ma sono “forzature” del funzionamento intrinseco di quel tipo di log.
Entra in gioco in questo caso il GELF, acronimo di Graylog Extended Log Format. Nato inizialmente proprio per essere utilizzato dal server Graylog (un sistema di logging e monitoring), è oramai sufficientemente standard da essere adottato anche da altri progetti (ad esempio Logstash lo fornisce come tipologia di input supportato).
A differenza del syslog, GELF è nato pensando anche ai container, e contiene indicazioni molto specifiche a riguardo. Se decidessimo di utilizzare questo sistema, però, ricordiamoci bene che:
- La lunghezza del singolo log (riga di log) non può superare i 1024 bytes. Quindi, se prevediamo dover loggare backtrace (come le eccezioni Java, ad esempio), questo sistema non è indicato
- I dati contenuti nel log non hanno tipo, quindi il formato non fa distinzione tra numeri e stringhe.
- L’invio dei log avviene tramite protocollo UDP. Questo è ottimo per assicurarsi che l’invio dei log non rallenti le applicazioni, ma è intrinseco nel protocollo che non c’è affidabilità sull’effettiva ricezione del log da parte del server
Detto questo, se i vostri requisiti lo consentono, sicuramente è interessante analizzare anche questa soluzione. Per iniziare a vedere com’è composto un log di questo tipo possiamo procedere in maniera molto semplice. Apriamo sul nostro server di logging (exthost) una porta udp in ascolto:
[vagrant@exthost ~]$ nc -u -l 1234
Mentre su uno dei nodi lanciamo un container semplice che scriva una semplicissima riga in output, così da vedere cosa viene loggato sul server:
[vagrant@snode1 ~]$ docker run --log-driver gelf --log-opt gelf-address=udp://172.30.0.20:1234 --log-opt gelf-compression-type=none alpine echo "Test log GELF"
Test log GELF
Ora, se andiamo a vedere l’output ottenuto sul server, notiamo che abbiamo ricevuto un json:
{
"version":"1.1",
"host":"snode1",
"short_message":"Test log GELF",
"timestamp":1.490805783064e+09,
"level":6,
"_command":"echo Test log GELF",
"_container_id":"99260b6f0e00733c4ef575e59aa9286e5e4ef9c1b6eae85314eb234b7d946e55",
"_container_name":"determined_ptolemy",
"_created":"2017-03-29T16:43:02.904838703Z",
"_image_id":"sha256:4a415e3663882fbc554ee830889c68a33b3585503892cc718a4698e91ef2a526",
"_image_name":"alpine",
"_tag":"99260b6f0e00"
}
Come possiamo notare, questo log contiene (di default) molte più informazioni legate ai container di quante ne possiamo trovare nel syslog; oltre al log abbiamo quindi indicazioni ad esempio su quale macchina ha inviato quel log, id e nome del container (così come dell’immagine) ed altro.
A questo possiamo aggiungere ulteriori informazioni tramite l’opzione tag del driver di Docker (–log-opt tag=valore): questa informazione andrà ad inserirsi nel campo “_tag” del json ricevuto.
Ma come possiamo utilizzare questi log? Come dicevamo, vengono presi in carico da diversi sistemi, uno di questi è proprio Logstash, un’applicazione sviluppata dal team di Elasticsearch che ha un funzionamento a plugin.
Sarà possibile dunque impostare il plugin gelf come input al fine di catturare i messaggi mandati da Docker in quel formato, filtrarli e fare tutto quello che si vuole con l’output, dalla scrittura in mero file di log fino all’invio ad un cluster Elasticsearch per la loro indicizzazione, permettendoci quindi di fare di questi log quello che vogliamo.
Vi forniamo il link alla lista di plugin di output di logstash per darvi un’idea di quello che potrete fare con i vostri preziosi log; una delle cose più interessanti di questo progetto è la possibilità di utilizzare più stream di output contemporaneamente, permettendoci quindi di implementare parallelismi di vario genere (pensate ad un log che viene inviato a logstash e da li mandato in “raw” su uno storage per il mantenimento nel lungo periodo e, magari solo parte di essa, inviato ad un Elasticsearch per l’indicizzazione e la creazione di statistiche).
Conclusioni
In questa seconda parte abbiamo messo parecchia carne al fuoco: ci siamo costruiti un laboratorio virtuale per simulare un’ambiente cluster swarm + un server di logging ed abbiamo analizzato due nuovi driver di logging forniti da Docker: syslog e GELF.
Quest’ultimo è la prima soluzione ritagliata realmente per i container, un log che ci fornisca informazioni aggiuntive sul nostro ambiente Docker senza che l’applicazione stessa -o noi tramite trucchi vari- debba fornire questi dati.
Nella prossima parte vedremo un altra ottima soluzione per la gestione di log provenienti da Docker, oltre a farci un’infarinatura su possibili driver utilizzabili su piattaforme cloud esterne.
Utente Linux/Unix da più di 20 anni, cerco sempre di condividere il mio know-how; occasionalmente, litigo con lo sviluppatore di Postfix e risolvo piccoli bug in GNOME. Adoro tutto ciò che può essere automatizzato e reso dinamico, l’HA e l’universo container. Autore dal 2011, provo a condividere quei piccoli tips&tricks che migliorano il lavoro e la giornata.










Lascia un commento