
È innegabile come il primo scoglio da affrontare quando ci si approccia a Kubernetes sia la sua complessità. Sebbene infatti cosa faccia k8s (come gli amici chiamano Kubernetes) sia bene o male chiaro a tutti, e cioè orchestrare container, i dubbi vengono sempre quando si pensa al come questo venga fatto nella pratica.
I Deployment, ad esempio. Sono una delle risorse base di Kubernetes, il cui scopo è raggruppare altre due componenti base: i Pod ed i ReplicaSet. I primi contengono il (o i) container che compongono l’applicazione, i secondi si accertano che il numero di Pod sia quello previsto.
A parole quindi tutto facile, o quasi, ma cosa succede “sotto al cofano”? Per capirlo ci viene in aiuto questo schema creato da Nived Velayudhan e Seth Kenlon che, nell’articolo A visual map of a Kubernetes deployment, mostrano i dettagli delle componenti parte dei Deployment:
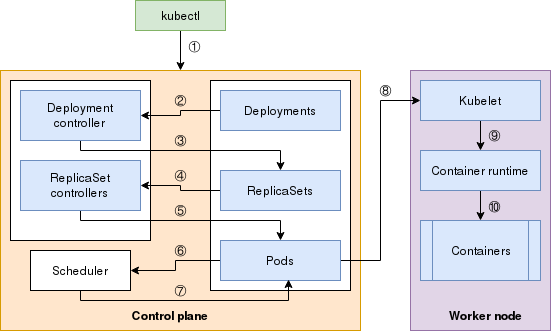
E step per step ecco quindi cosa avviene, partendo dal control plane, ossia l’insieme dei nodi “master” parte dell’installazione Kubernetes:
- kubectl contatta le API di k8s per avviare la creazione del Deployment (step 1).
- Il processo watcher che osserva le risorse Deployment ingaggia il componente Deployment controller che avvia la creazione del ReplicaSet (step 2 e 3).
- Il processo watcher che osserva le risorse ReplicaSet ingaggia il componente ReplicaSet controller che, sulla base delle richieste in termini di numeri di replica, avvia la creazione dell’elemento Pod (step 4 e 5).
- A questo punto viene ingaggiato lo Scheduler che si preoccupa di assegnare i Pod ai vari nodi e restituisce l’informazione al control plane (step 6 e 7).
- La palla passa a questo punto al (o ai) nodo worker, in cui la componente kubelet viene ingaggiata dal control plane affinché, date le specifiche ricevute, ingaggia la propria container runtime per arrivare, infine, alla creazione del vero e proprio container (step 8, 9 e 10).
Fine della storia. Vien da sé che il livello di dettaglio descritto qui potrebbe essere ancora più approfondito, ad esempio andando ad esplorare quando e come etcd (centrale nel mantenimento della fotografia dello stato attuale del cluster) viene ingaggiato nelle varie fasi, ma il flusso descritto permette di avere una fotografia molto chiara degli attori e delle fasi nella creazione di una componente così importante nell’economia di Kubernetes.
Grazie quindi agli autori del diagramma!
Da sempre appassionato del mondo open-source e di Linux nel 2009 ho fondato il portale Mia Mamma Usa Linux! per condividere articoli, notizie ed in generale tutto quello che riguarda il mondo del pinguino, con particolare attenzione alle tematiche di interoperabilità, HA e cloud.
E, sì, mia mamma usa Linux dal 2009.












Lascia un commento