

Given enough eyeballs, all bugs are shallow
Con sufficienti sguardi, tutti i bug emergono
È la Linus’s law: l’affermazione del creatore del Kernel Linux secondo il quale non esistono bug impossibili da scovare e, considerato che a parlare è chi gestisce il progetto open-source più grande del mondo, c’è da fidarsi.
Ma come si arriva all’identificazione di un bug? Più precisamente, quanto ci mette – in media – un progetto come il Kernel Linux a rilevare un problema?
Se lo è chiesto il ricercatore Jenny Guanni Qu, il quale ha analizzato 125.183 bug relativi a 20 anni di sviluppi nel Kernel Linux per ricavare delle statistiche in merito alle tempistiche di rilevazione degli stessi.
Il risultato dell’analisi è riassunto in questa tabella la quale menziona VulnBERT, ossia un modello costruito appositamente per l’analisi che predice quando un commit introduce una vulnerabilità e CodeBERT, un modello di Microsoft in grado di comprendere sia il linguaggio naturale che quello di programmazione:
| 125,183 | Patch con tag Fixes: associabili a dei bug |
| 123,696 | Record ritenuti validi dopo il filtraggio (età tra 0 e 27 anni) |
| 2.1 years | Tempo medio in cui un bug rimane non rilevato |
| 20.7 years | Tempo massimo per la rilevazione di un bug (un buffer overflow di ethtool) |
| 0% → 69% | Bug scoperti entro l’anno, comparazione tra il 2010 e il 2022 |
| 92.2% | Percentuale di bug storici rilevati da VulnBERT nell’anno 2024 |
| 1.2% | Percentuale di falsi positivi (contro il 48% rilevato da CodeBERT) |
Interessante anche la distribuzione del ciclo di vita dei bug, riassunta in questa immagine:
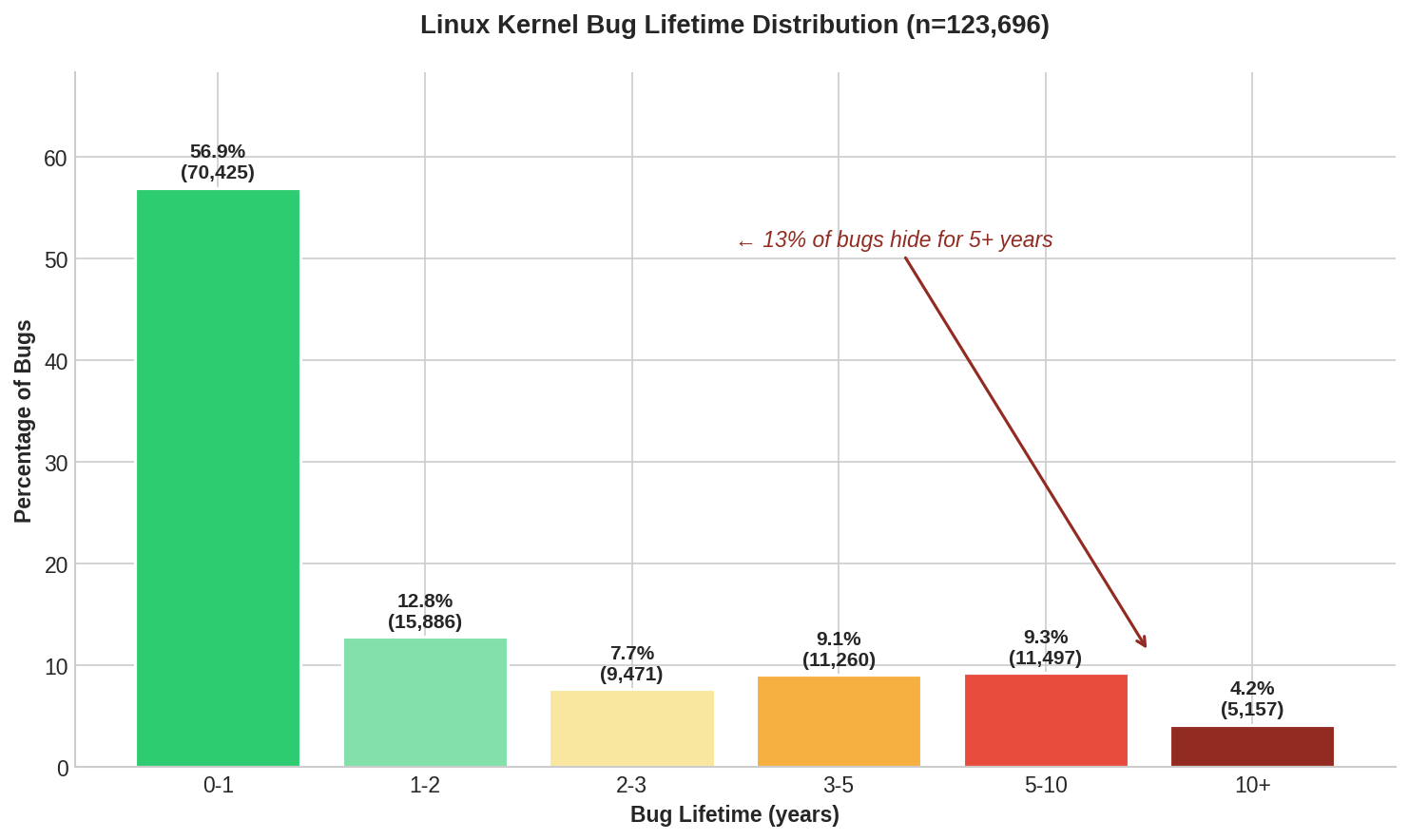
Come è facile immaginare, un’analisi di questo tipo, tutt’altro che triviale, è soggetta a numerosi fattori di influenza, e l’articolo originale spiega quanto complicato è stato creare il modello di comparazione, il quale ha però permesso di formulare alcune interessanti conclusioni.
Alcuni bug rimangono nascosti per più tempo rispetto agli altri. In testa ci sono le race-condition, ossia i bug che non sono riproducibili a comando, seguiti dagli integer-overflow. Entrambe queste categorie superano in genere i due anni, ed il motivo per cui questi bug sono più difficili da rilevare è ovviamente che sono più difficili da riscontrare (non solo quindi da riprodurre).
Non troppo sorprendentemente a questa categoria appartengono spesso i problemi di network (perché in fondo sì, è sempre colpa del network), e per dimostrare questo viene presentato un case study a proposito del più antico bug di networking, introdotto nel 2006 e sistemato nel 2025.
In chiusura ecco la proposta: è possibile rilevare automaticamente questi bug?
E proprio il modello sviluppato dall’autore potrebbe essere un tentativo introdotto nel processo di sviluppo del Kernel Linux e alimentato nel tempo per crescere a seconda delle esigenze. I risultati presentati sono promettenti, chissà se questo impiego dell’AI, a tutti gli effetti utilizzata “come un altro strumento” piacerà a Linus Torvalds ed ai maintainer del Kernel?
Da sempre appassionato del mondo open-source e di Linux nel 2009 ho fondato il portale Mia Mamma Usa Linux! per condividere articoli, notizie ed in generale tutto quello che riguarda il mondo del pinguino, con particolare attenzione alle tematiche di interoperabilità, HA e cloud.
E, sì, mia mamma usa Linux dal 2009.














Lascia un commento