
 Cominciamo con una premessa: faremo una introduzione lunghetta ma necessaria, soprattutto per chi non ha ben presente alcune questioni tecniche. Abbiate pazienza!
Cominciamo con una premessa: faremo una introduzione lunghetta ma necessaria, soprattutto per chi non ha ben presente alcune questioni tecniche. Abbiate pazienza!
Tutti noi che usiamo linux abbiamo incrociato almeno una volta un file con estensione .tar: questi sono file di archivio, che comprendono a loro volta file (e cartelle). Il file è generato con il comando tar (Tape ARchive, archivio da nastro), che fa la sua apparizione su Unix v7 nel lontano 1979, pensato per archiviare i dati nei mezzi che allora erano più efficienti, le bobine a nastro, e che da allora ha subito ben poche modifiche – anche nella versione GNU che troviamo su Linux.
I filesystem di solito ragionano a blocchi di dimensione fissa (comunemente 4kB), ed ogni blocco può appartenere ad un solo file; succede quindi che, se il file non è un esatto multiplo della dimensione del blocco, dello spazio non viene utilizzato ma -di fatto- buttato via. Il formato tar non è altro che un accodamento di tanti file o cartelle (e loro descrizioni nel filesystem, i metadati) in uno solo. Anche solo questo permette di recuperare quello spazio, ma ovviamente una compressione fa un lavoro migliore. E infatti normalmente viene anche compresso (molti avranno più familarità con estensioni come .tar.gz, .tar.bz2 o .tar.xz): l’operazione è tanto comune che la versione GNU di tar gestisce autonomamente anche compressione e decompressione. L’usare un file di archivio e non tanti piccoli file permette anche di rendere la compressione stessa più efficacie, in quanto più dati si hanno a disposizione, più è grande la probabilità che alcuni di essi si ripetano (cosa molto cara ai compressori).
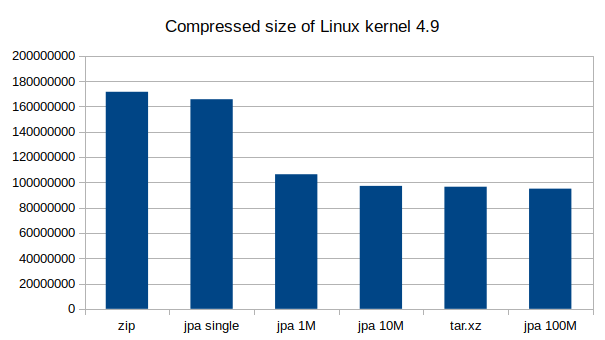
Il binomio tar+xz è attualmente quello più performante (come rapporto di compressione, perché è anche quello più lento, e di molto). Un esempio fatto in casa con i sorgenti del kernel (di Gentoo):
linux-4.9.0-gentoo 1351MB linux-4.9.0-gentoo.tar 1281MB linux-4.9.0-gentoo.tar.zip 307MB linux-4.9.0-gentoo.tar.gz 307MB linux-4.9.0-gentoo.tar.bz2 240MB linux-4.9.0-gentoo.tar.xz 136MB
Come si vede, la differenza è notevole tra formato e formato: il solo tar recupera qualche MB su oltre un GB, mentre tar.xz comprime risparmia il 90% di spazio, riducendo ad un decimo la dimensione originaria.
Proprio per le caratteristiche del formato tar, soprattutto da compresso, alcune operazioni facili con altri formati (ZIP, per nominarne uno) risultano molto scomode: solo per sapere quali file siano contenuti nel tar è necessario decomprimere e leggere tutto, dall’inizio alla fine. Se invece si volesse estrarre solo un file, già sapendo che è contenuto nel tar, si dovrebbe prima decomprimere tutto il tar e poi leggere il .tar almeno fino al punto in cui si trova il file desiderato.
Con l’inizio dell’anno (o, per essere pignoli, la fine dell’anno scorso ;-)), uno sviluppatore finlandese, Jussi Pakkanen, ha pubblicato il suo compressore jpak con il suo formato jpa, che usa lo stesso algoritmo di compressione di xz, ma al quale unisce qualche furbizia. Innanzitutto prevede la possibilità di comprimere intere directory, e non solo file (cosa non così scontata); poi prevede la creazione un indice (TOC, Table Of Contents) dei file; invece di comprimere l’intero file, da inizio a fine, questo viene diviso in vari pezzetti autonomi di dimensione predefinita, permettendo sia la compressione che la decompressione in parallelo (usando tutti core delle macchine recenti, per esempio); essendo autonome le parti, è possibile andare a cercare il file solo nella parte in cui si trova, o accedere a più parti del file contemporaneamente. Lo svantaggio di questo approccio è una certa perdita di efficacia (ricordate poco sopra?), ma dai test pubblicati questa perdita è piuttosto piccola.
L’idea di spezzettare il file in parti autonome non è nuova: pigz, pbzip2 e pxz sono le versioni di gzip, bzip2 e xz che sfruttano la stessa idea per velocizzare la fase di compressione, ma ci sono due differenze fondamentali:
- i processi paralleli sono solo per la fase di compressione, per mantenere in decompressione la compatibilità con il programma standard non parallelo;
- il file da comprimere o decompresso è ancora in formato .tar, con tutte le sue limitazioni.
L’autore ha postato queste considerazioni ponendo (e ponendoci) una domanda: che sia venuto il momento di mettere da parte tar? La nostra risposta è forse, ma già altri ci stanno provando (DAR), e non è detto affatto che vinca jpak. Per ora il progetto è stato solo presentato e non é ancora pronto per una prova sul campo: vedremo, quando (e se) sarà maturo, quanto potrà dar battaglia ad un formato usato da più di 35 anni.

Ho coltivato la mia passione per l’informatica fin da bambino, coi primi programmi BASIC. In età adulta mi sono avvicinato a Linux ed alla programmazione C, per poi interessarmi di reti. Infine, il mio hobby è diventato anche il mio lavoro.
Per me il modo migliore di imparare è fare, e per questo devo utilizzare le tecnologie che ritengo interessanti; a questo scopo, il mondo opensource offre gli strumenti perfetti.










Lascia un commento