
 Secondo un recente studio condotto dai team della University of California, dalla Czech Technical University, dalla Northeastern University, Irvine e dalla Microsoft Research, oltre l’82% del codice presente su GitHub sarebbe un mero clone di file precedentemente creati.
Secondo un recente studio condotto dai team della University of California, dalla Czech Technical University, dalla Northeastern University, Irvine e dalla Microsoft Research, oltre l’82% del codice presente su GitHub sarebbe un mero clone di file precedentemente creati.
Su 4.5 milioni di progetti esaminati (non-forked), di 482 milioni di file solo poco più del 17% si è rivelato essere composto da codice unico.
Lo studio è stato condotto confrontando gli hash dei file su progetti scritti in Java, JavaScript, Python e C++, queste le percentuali di codice duplicato:
- JavaScript, 94%
- C++, 73%
- Python, 71%
- Java, 40%
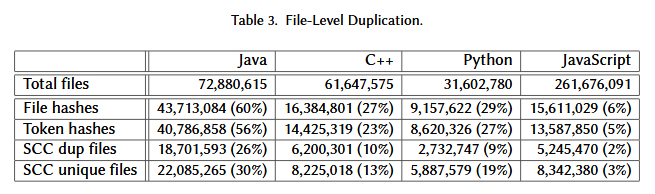
Nella tabella sono indicati anche i confronti fatti utilizzando i token hash che prende in considerazione match parziali nel contenuto del file, ed i risultati non variano di molto.
Non stupisce molto che il codice di JavaScript sia presente milioni e milioni di volte sempre uguale e la “colpa” è da attribuire ad NPM, il package manager per Node.js, che include oltre 350.000 librerie.
Il team ha reso disponibili i dump MySQL utilizzati per la ricerca e pubblicato un documento “DéjàVu: A Map of Code Duplicates on GitHub” con tutti i dettagli dello studio.
Git e GitHub sono nati per incoraggiare i fork ma la situazione attuale è ben diversa: un enorme copia-incolla di codice e addirittura di intere librerie! Il tutto perché, solitamente, chi crea un nuovo progetto tende a committare sul repository anche tutte le librerie, come se fossero parte del codice dell’applicazione.
Forse anche noi abbiamo una piccola parte in quell’82% di duplicati…

Affascinata sin da piccola dai computer (anche se al massimo avevo un cluster di Mio Caro Diario), sono un’opensourcer per caso, da quando sono incappata in Mandrake. Legacy dentro. Se state leggendo un articolo amarcord, probabilmente l’ho scritto io.











Lascia un commento