
Quando si parla di Kubernetes tra neofiti, così come quando si parlava di OpenStack qualche anno fa (sembra un’era geologica, ma la prima release di OpenStack è del 2010), c’è sempre un misto di fascinazione e paura.
Cos’è questa cosa di cui tutti parlano? Mi serve? È utile? In particolare: la posso capire? Domande lecite e legittime, le cui risposte non sono poi così semplici da interpretare, quando le si trova.
Il problema è che all’atto pratico Kubernetes dovrebbe essere considerato, in maniera lucida, unicamente per quello che è: una tecnologia. Con pregi e difetti che andrebbero valutati sempre e solo sulla base delle proprie esigenze, non in base ai trend topic di Twitter.
Succede sempre così? Quasi mai.
Dovrebbe? Sempre.
Sono in tanti a porsi domande e tanti provano a dare risposte, c’è chi ad esempio boccia Kubernetes per la maggioranza dei casi, evidenzando aspetti negativi che ciascuno dovrebbe tenere in considerazione nel valutare questa tecnologia. Dalla necessità di macchine multiple, passando per le 580.000 linee di codice Go su cui è basato. Dalla complessità intrinseca (concettuale, architetturale, operazionale ed a livello di configurazione) a quella dei deploy, per concludere come in generale i microservizi siano una cattiva idea.
Tutto male quindi? Occorre lucidità.
Bollare l’intero progetto come non necessario solo perché questo richiede più macchine per essere erogato è un ragionamento piuttosto limitante. Certo, la gestione potrebbe rivelarsi complicata, ma per sfruttare quelli che sono i pregi del progetto (che l’autore comunque menziona) quali la scalabilità e la disponibilità dei servizi si fa presto a concludere come la coperta sia corta: è impossibile pretendere di scalare ed essere sempre disponibili senza avere un’architettura ampia. Ovviamente poi, questa va gestita.
Infine la questione complessità: nel capire la struttura, nell’organizzare i deploy, nello sviluppare in generale i microservizi (bollati dall’autore come inutili, per via del fatto che è complicato scriverne di efficienti e funzionali).
Come per tutti i progetti enormi come Kubernetes, prendere il toro per le corna cercando di sfruttarne tutte le funzionalità è davvero un approccio poco raccomandabile. È oggettivo come alcune dinamiche di funzionamento di k8s vadano comprese, assimilate e diluite in base al proprio know-how, in modo da non sentire il cuore accelerare di fronte a immagini come questa:
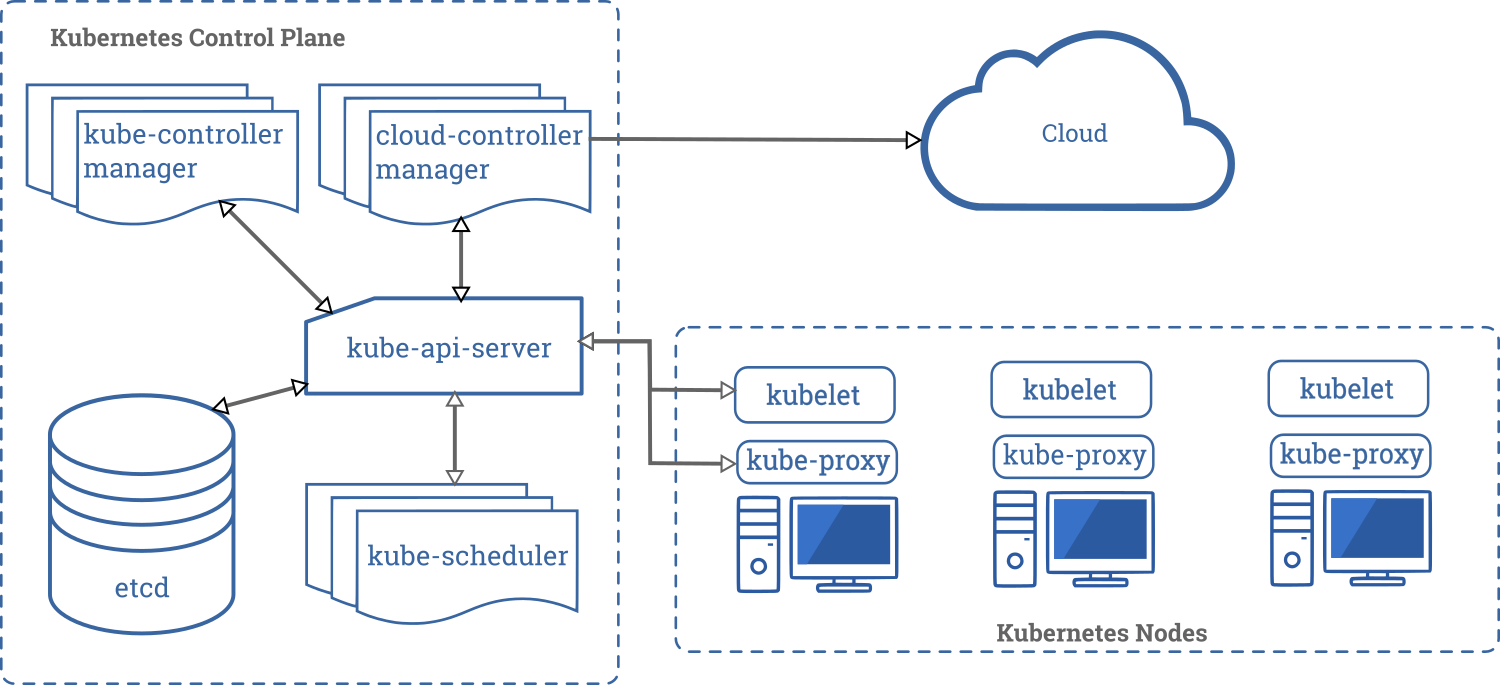
Approcciarsi cercando di capire cosa, rispetto a quanto è necessario erogare, possa beneficiare di un utilizzo all’interno di Kubernetes, magari affiancando inizialmente la soluzione a quelle esistenti ecco, potrebbe essere un’idea.
Per quanto complessa l’architettura nell’immagine qui sopra (che arriva dalla documentazione ufficiale del progetto) può sembrare, è di fatto è possibile partire a testare le cose con due sole macchine.
Il buon senso dunque: se l’esigenza è quella di avere 10 container che erogano un servizio al momento in funzione su una singola macchina, allora forse no, la complessità introdotta da k8s è troppa, viceversa se si ha necessità di scalare ed applicazioni che necessitano di tale approccio allora l’idea di avere uno strumento che in maniera automatizzata si occupi di aumentare (o diminuire) la potenza di fuoco basandosi su precise metriche potrebbe essere irrinunciabile.
A proposito di questo, noi di MMUL stiamo portando avanti un progetto aperto per creare un’installazione standard di Kubernetes mediante Ansible. Chi volesse partecipare è il benvenuto.
Da sempre appassionato del mondo open-source e di Linux nel 2009 ho fondato il portale Mia Mamma Usa Linux! per condividere articoli, notizie ed in generale tutto quello che riguarda il mondo del pinguino, con particolare attenzione alle tematiche di interoperabilità, HA e cloud.
E, sì, mia mamma usa Linux dal 2009.












Lascia un commento