
Agli albori dell’informatica, la parte più fisica più costosa di un sistema era spesso la RAM, tanto da risultare uno dei parametri principali nella valutazione delle capacità di un computer. Il Commodore 64 si chiamava così per i suoi 64 KB di RAM, per esempio!
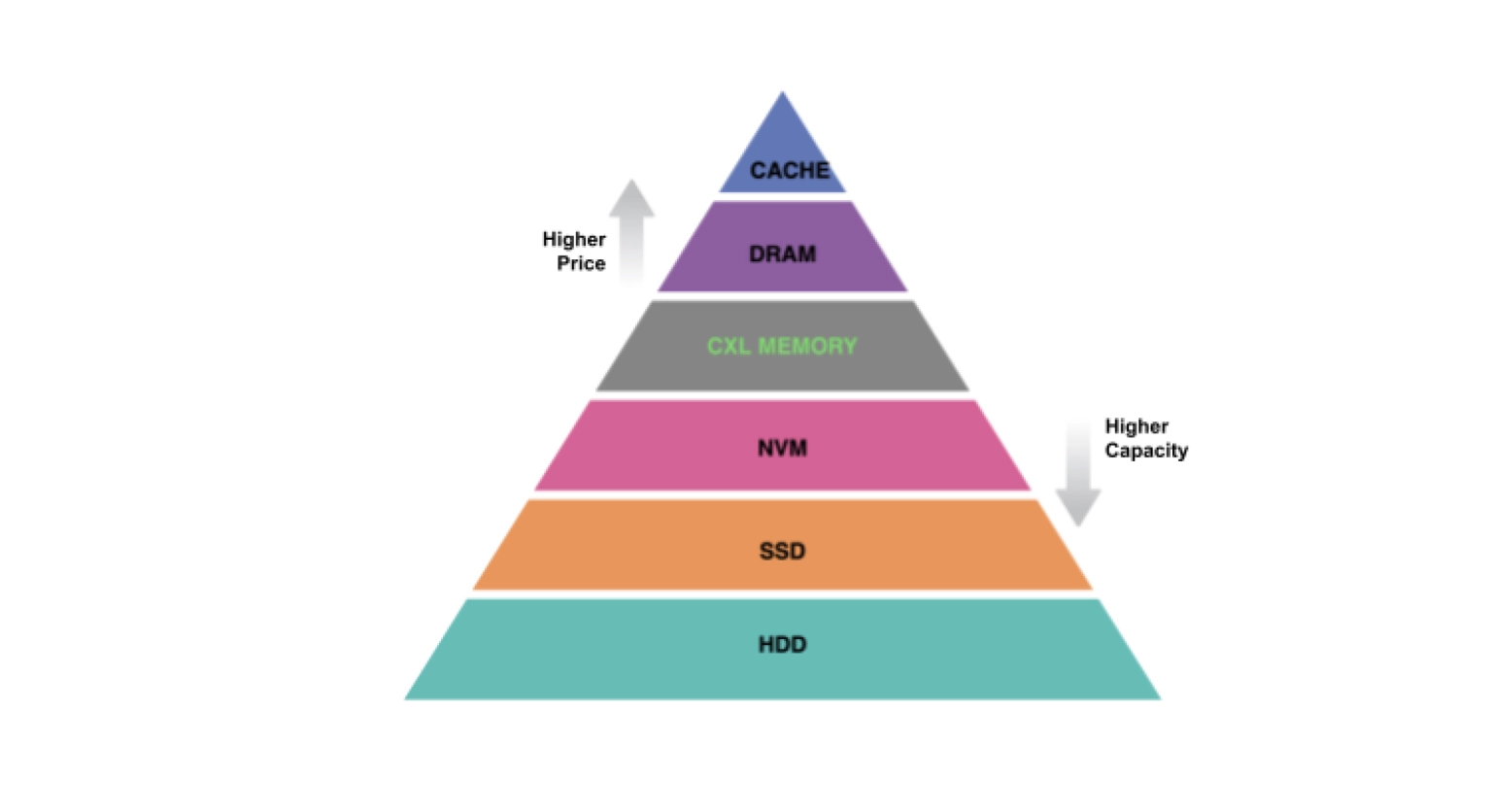
Linux – come i sistemi Unix – ha un meccanismo per aumentare artificialmente la memoria disponibile: la swap. In poche parole, si tratta di prendere un pezzo di disco e permettere di parcheggiare lì i dati meno usati. Lo scambio è tra prestazioni (RAM molto veloce, disco molto lento) e dimensioni (RAM molto piccola, disco molto grande), in modo da avere a sufficienza entrambi.
Un paio di decenni fa c’è stato un boom nelle dimensioni della RAM usabili sui sistemi, dovuto al calo di prezzo per chip: della swap ci siamo (quasi) dimenticati. Anche perché la differenza di prestazioni tra RAM e Hard Disk è andata sempre più aumentando, giustificando sempre meno lo scambio.
Fatte queste premesse, oggi vi raccontiamo di Meta che ha presentato sul suo blog TMO (Transparent Memory Offloding – scarico della memoria transparente). Il concetto base è lo stesso della swap: Facebook ha rilevato che negli ultimi anni il costo della sola RAM dei propri server stava tornando ad essere importante, dichiarando di prevedere che possa arrivare al 33% del costo complessivo dell’infrastruttura, davvero una bella fetta. Ecco quindi che poter usare altri supporti di memorizzazione al fianco della RAM potrebbe risultare un grande aiuto.
Perché inventare un nuovo meccanismo e non usare la swap, che è tradizionale, già presente e disponibile? Per un problema di anzianità: quella soluzione è stata tarata per gli HD, e tende ad usarli il meno possibile, per via delle basse prestazioni. Quindi, è poco efficiente.
Negli ultimi anni sono diventati disponibili altri supporti con prestazioni maggiori, come SSD ed NVMe, o tecniche di compressione della RAM come zswap, tutte cose che la swap vede come paritetiche, uguali: non può differenziare il comportamento e usare ogni dispositivo nel modo appropriato.
La tecnologia TMO presentata, invece, cerca di essere più intelligente, adattando il metodo di offload (lo spostamento dei dati dalla RAM ad un altro supporto) in base alle caratteristiche dell’applicazione e dei dati.
In realtà, al momento la scelta è fatta a mano: applicazione per applicazione viene indicato a TMO come fare offload dei dati relativi a quell’applicazione, ma la strada è tracciata per rendere il tutto automatico.
I dati basati su un anno di uso all’interno di Facebook sono piuttosto interessanti: mediamente, dicono, si risparmia tra il 20 % e il 32 % della memoria – che vuol dire anche consumi energetici più bassi.
La tecnologia comprende un nuovo driver per il Kernel ed un demone in user-space che gli dia indicazioni: non sembra un impegno esagerato.
Se davvero TMO è in buono stato, possiamo aspettarci di trovarlo disponibile in poco tempo, diciamo un paio d’anni, anche sui nostri sistemi. Dove fargli usare un po’ di memoria compressa, un po’ di NVMe, un po’ di SSD. E, forse, qualcuno ha ancora un HD in funzione… no?

Ho coltivato la mia passione per l’informatica fin da bambino, coi primi programmi BASIC. In età adulta mi sono avvicinato a Linux ed alla programmazione C, per poi interessarmi di reti. Infine, il mio hobby è diventato anche il mio lavoro.
Per me il modo migliore di imparare è fare, e per questo devo utilizzare le tecnologie che ritengo interessanti; a questo scopo, il mondo opensource offre gli strumenti perfetti.














Lascia un commento